手撸神经网络系列之——Tensor类的封装思路
该系列的前一篇文章提到了计算图以及误差在计算图中的传播方式,计算图作为一种图结构,在代码实现上也是比较容易,只需要合理定义图的节点类,再实现一些方法即可,本文将简单讲解一下我自己写的计算图的节点类,语言自然是Python,代码写的比较垃圾,希望高手们多多包涵!
本系列全部代码见下面仓库:

如有算法或实现方式上的问题,请各位大佬轻喷+指正!
从这篇文章开始,我将会陆陆续续贴一些代码,手机端的朋友们对不住了!建议前往电脑端浏览器进行浏览。
初始化
作为计算图的节点,如前面提到的,需要包含的基本attribute有以下:
- 节点的数据
非常容易理解,如前面计算图中提到的$x, y, z$这些数,就是其节点的数据,不过,实际操作中,这些数据都是张量,神经网络中为了并行化提速,一般不会一个数一个数地算,而是直接写成矩阵、张量形式,进行矩阵、张量运算(矩阵即二维的张量)。
- 节点是否需要梯度
这是个布尔值,众所周知,在计算图中有一些数是需要计算梯度的,比如神经网络的待训练参数、待训练参数经过运算得到的其他数。一句话概括,从计算图的根节点出发,到达待训练参数叶子的路径上的每一个节点,都需要计算梯度(不然梯度怎么传递到叶子?)。另外有很多常数张量,例如所有输入到神经网络里的训练数据,它们就不需要梯度。因此,加入这个布尔变量是为了减少不必要的梯度计算。
- 节点的梯度
这也是个张量,形状与节点的数据形状相同,表示计算图的根节点对此节点的梯度值。在参数梯度下降更新的时候会用到这个值。
- 节点的子节点
这是图结构中最基本的东西了,用来存放该节点的所有子节点,即计算图上指向该节点的所有其他节点,或者说,该节点是通过所有的子节点的某种运算得到的。
- 节点的梯度反传函数
这个属性用来记录该节点是其子节点通过何种运算得到的,例如$a+b=c$,就在$c$节点上记录梯度计算函数为“加法”,因为我们只有知道节点是通过何种运算得到的,才能顺利将自己的梯度前推至其子节点上。这里的一个注意点是,一个节点的梯度反传函数并非用以计算其自身的梯度,而是用以将自身的梯度向前传播至其每个子节点。
下面给出我的类初始化方法:
class Tensor(object):
def __init__(self, data, dtype=None, requires_grad=False):
if isinstance(data, Tensor):
data = data.data
if dtype is None:
self.data = np.array(data)
if self.dtype == float64:
self.data = self.data.astype(float32)
else:
self.data = np.array(data, dtype=dtype)
assert 'float' in self.dtype.name or not requires_grad, \
'Only Arrays of floating point dtype can require gradients'
self.requires_grad = requires_grad
self.grad_fn = None
self.children = []
self.grad = None
self._retain = False可不必纠结于上面代码的细节(中间部分逻辑写的很无脑),只需知道以下:
在初始化的时候,需要传入节点的数据(我用的class就是numpy.ndarray),可指定数据类型,以及是否需要梯度,后面初始化的requires_grad即该节点是否需要梯度;grad_fn为梯度反传函数,初始值是None;children为子节点,因为children的数量是不确定的,故这里定义为一个列表;grad是节点的梯度,初始值也是None。最后一个_retain参数我之前没提到,该参数其实是用来决定此节点是否需要把梯度值存储到grad属性上。那么_retain参数是否和requires_grad重复了呢?各位可以思考一下这个问题,后文会揭晓答案。
张量运算
作为张量类,运算方法肯定是必不可少的,而因为我们用来构建计算图的方法是动态图,在每一次运算中,都需要在图上连几条箭头,所以在定义运算方法的时候需要做一些操作。
这里给一个我定义加法的例子:
def __add__(self, other):
if isinstance(other, Number):
result = Tensor(self.data + other, dtype=self.dtype, requires_grad=self.requires_grad)
else:
result = Tensor(self.data + other.data, dtype=self.dtype, requires_grad=self.requires_grad or other.requires_grad)
if result.grad_enable:
result.children = [(self,), (other,)]
result.grad_fn = AddBackward()
return result
def __radd__(self, other):
return self.__add__(other)为了避免繁杂的讨论,我们限定加法以及后面几乎所有的二元运算的other对象只能是两种类型:Number与Tensor自身。在__add__方法中,首先要得到计算结果的data属性,即它的数据,这个比较简单,直接把自己的data和加数的data加起来就好了。但有一个问题,如果加数只是普通的数字,不是Tensor类,它没有data这个attribute,这样是会报错的,这里就对加数的类型进行了讨论,如果是数字,那么直接把data和它加起来就行。
第二点是,如何判断得到的结果是否需要梯度,控制该属性的attribute是requires_grad参数,在初始化时可以作为参数直接传入Tensor类,回想一下前面提到的“从计算图的根节点出发,到达待训练参数叶子的路径上的每一个节点,都需要计算梯度”,这意味着,如果某个参数需要梯度,那么只要有它参与的任何运算得到的结果,也会需要梯度(不然梯度路径断了,传不到叶子)。在加法过程中,如果加数是普通的数字,那么加数不需要梯度,我们只需要判断节点自身是否需要梯度即可,故结果的requires_grad自然就是节点自身的requires_grad;如果加数也是个Tensor,通过一样的逻辑可以得到,结果的requires_grad相当于加数和自己的requires_grad属性做一个或运算,只要它们随便哪个需要梯度,那么得到的结果必然需要梯度。
第三点是children的放置,刚才只是给出了运算结果的data以及其是否需要计算梯度,相对于定义了计算图的一个节点,接下来当然是要把这个节点连到计算图上去了,方法也很简单,只要在children里把参与加法操作的两个数放进去,第一个是自身,第二个就是加数,那么children就应该是[self, other]。然而我代码里面是这样的:[(self,), (other,)],是俩元组类型,元组的第0位是真正的child,而后面的位置我本来是打算预留一些其他信息的,有一些特殊的运算,在算梯度时需要知道除了运算数以外的信息,例如transpose(矩阵的转置运算在张量上的推广)运算在反传梯度的时候,就需要知道之前是交换了哪几个轴,光知道运算数是不够的,像这类信息,我在一开始设计的时候就把它存在children这里,后面为了在反向传播代码中保持统一,就对所有的运算都采用这样的存法了。
最后也是最重要的,梯度反传函数的指定,把运算结果节点接上去以后,需要指定其梯度反传函数,说白了就是这个结果通过什么运算得来的,这里就是加法运算,对于每一个涉及到的运算,我都在另一个文件里定义了一个backward函数,对于加法,就叫做AddBackward(即Add操作的反向传播),可以暂时当做是指明了“加法”。
这里有个小问题,在后面构建计算图之前,我用的判断语句是if result.grad_enable,而不是if result.requires_grad,这是什么玩意?前面也没提到啊?这其实是我强行模仿PyTorch的产物,它有一个称为no_grad的运算模式,该模式下,所有的梯度运算都将被忽略,在测试模型的时候非常有用,可以省下大量搭建计算图需要的空间和时间,这里的grad_enable将判断当前是否处于此模式下,以及result是否需要梯度,这两个布尔值只有全部为True,才会进入下面计算图的构建环节。
其余的张量运算,不想举例了!其实都差不多,可以翻看我的源码文件,写的非常冗杂,请见谅,若有疑问可以直接问我!
反向传播
张量类最重要的功能就是反向传播,我定义了一个backward函数在最后。
def backward(self, grad=None):
if not self.grad_enable:
return
stack = [(self, grad)]
while stack:
item, grad = stack.pop()
if item.is_leaf:
continue
if grad is None:
assert item.size == 1, 'grad can be implicitly created only for scalar outputs'
grad = np.ones_like(item.data)
if item._retain_grad:
item.grad = Tensor(grad)
for i, child in enumerate(item.children):
child_tensor = child[0]
if isinstance(child_tensor, Tensor) and child_tensor.requires_grad:
child_grad = item.grad_fn.calculate_grad(grad, item.children, i)
if child_tensor._retain_grad:
if child_tensor.grad is None:
child_tensor.grad = Tensor(np.zeros_like(child_tensor.data), dtype=child_tensor.dtype)
child_tensor.grad = child_tensor.grad + Tensor(child_grad, dtype=float32)
stack.append((child_tensor, child_grad))
return该函数实现了一个有向图的深度优先搜索。stack列表用来充当栈,维护需要遍历的节点。
for循环中我遍历了当前搜索节点的所有children节点,对每一个类型为Tensor且需要计算梯度的child,主要做了以下两件事:
- 通过节点的
grad_fn(梯度反传函数)的calculate_grad方法,来计算child的梯度。这里的calculate_grad,是梯度反传函数计算梯度的方法,后面将会重点提到。 - 将
child_tensor以及前面计算出来的对该子节点的偏导数放入栈中,以此实现图的深度优先遍历,把梯度从根节点一步步传回到叶子。
中间有一条判断语句:if child_tensor._retain_grad,这即是我前面提到的,判断是否需要存储梯度,所谓存储梯度,其实就是把算出来的梯度叠加其的grad属性上。如果子节点child_tensor需要存储梯度,那么先判断其梯度是否为None,若为None,将其初始化为零张量。最后把得到的子节点的梯度child_grad加上去就好了!对于不需要存储梯度的节点,就省去了这一步,也节省了空间支出。那么,回到前面留下的那个悬念,这个_retain_grad参数是否就和requires_grad参数重复了呢?其实不然,对于在反向传播路径上的非叶子节点而言,它们自然需要计算梯度,也就是requires_grad为True,但一般情况下,它们不需要把自身梯度记录下来,这是因为后面梯度更新的时候并不需要更新它们,对这些路径上的非叶子节点而言,它们在每次算来的梯度(偏导数)后,只需要把梯度直接向子节点传下去即可。也就是说:
一般情况下,只有叶子节点,才有必要存储梯度!中间结果的节点只需要计算梯度,不需要存储梯度。
下面给一个简单的例子来可视化一下$e=(a+b)\times a$的计算图中,计算$\frac{\partial e}{\partial a}与\frac{\partial e}{\partial b}$的过程模拟,假设
并且为了清晰起见,节点的主要属性会被记录在其中,且过程中所有节点均将累计梯度存在节点里,当前正在进行反向传播的路径将会进行加粗显示,该次反向传播中发生改变的梯度值也会加粗显示。
需要注意的是,下面计算图中出现的两块“a”节点,事实上是同一个节点,这里将其分开是为了让计算图的结构更清晰。
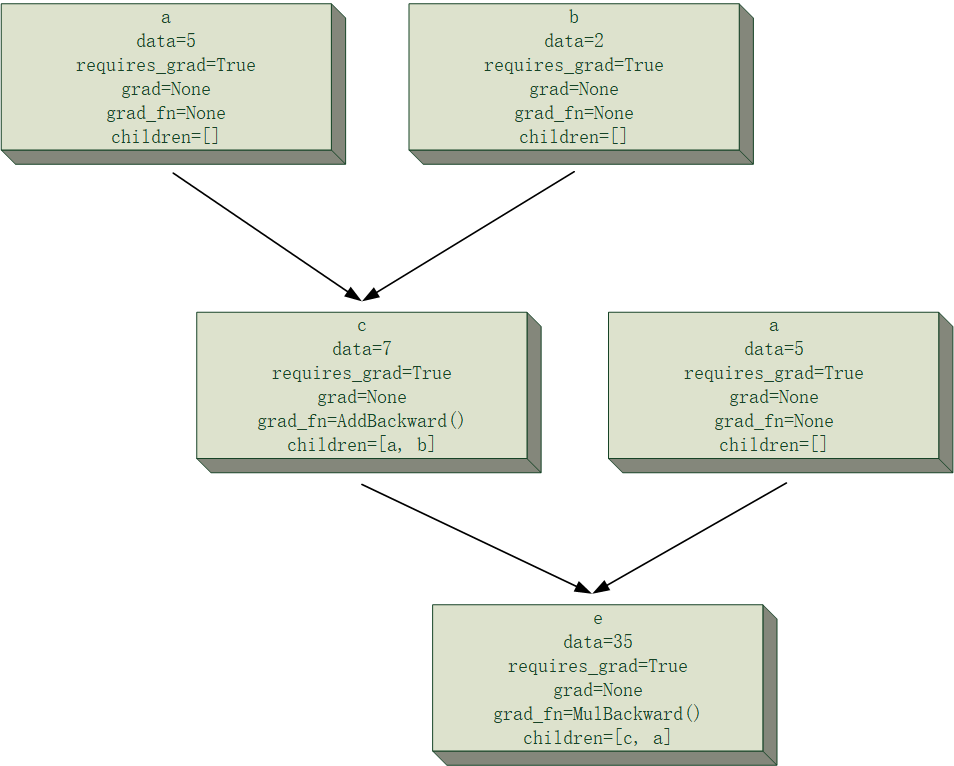
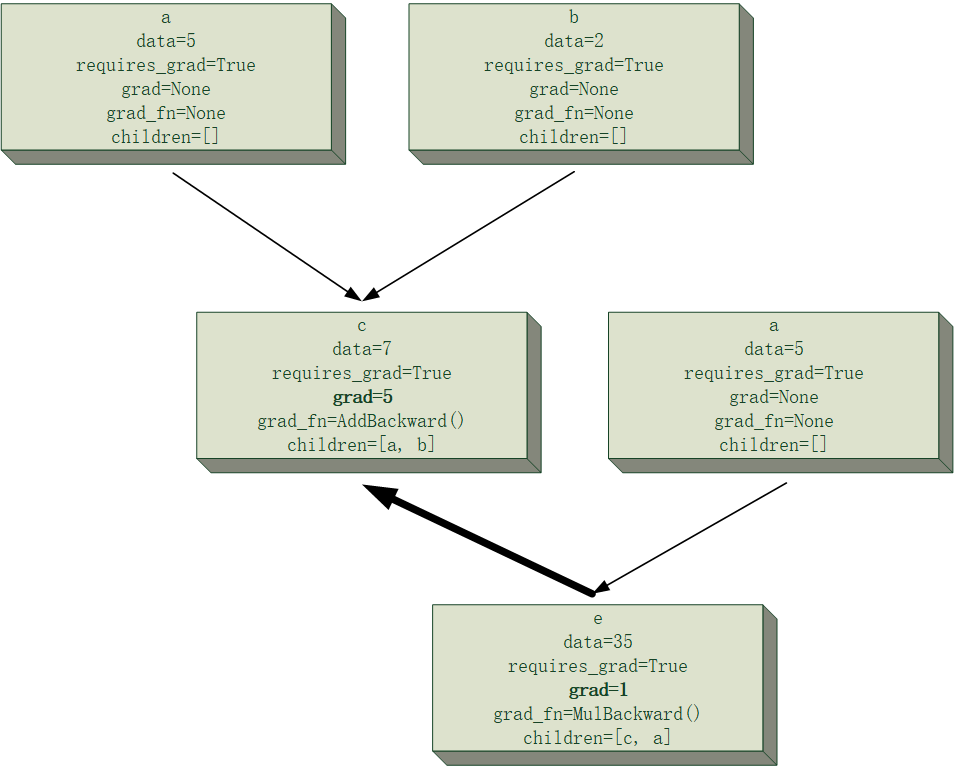
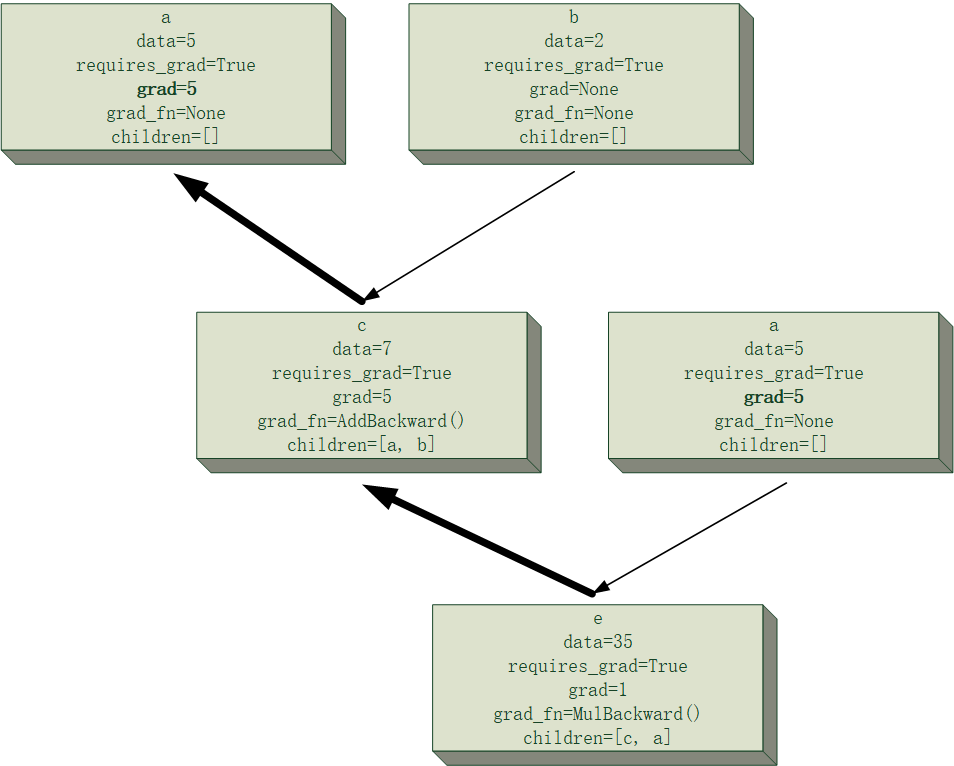
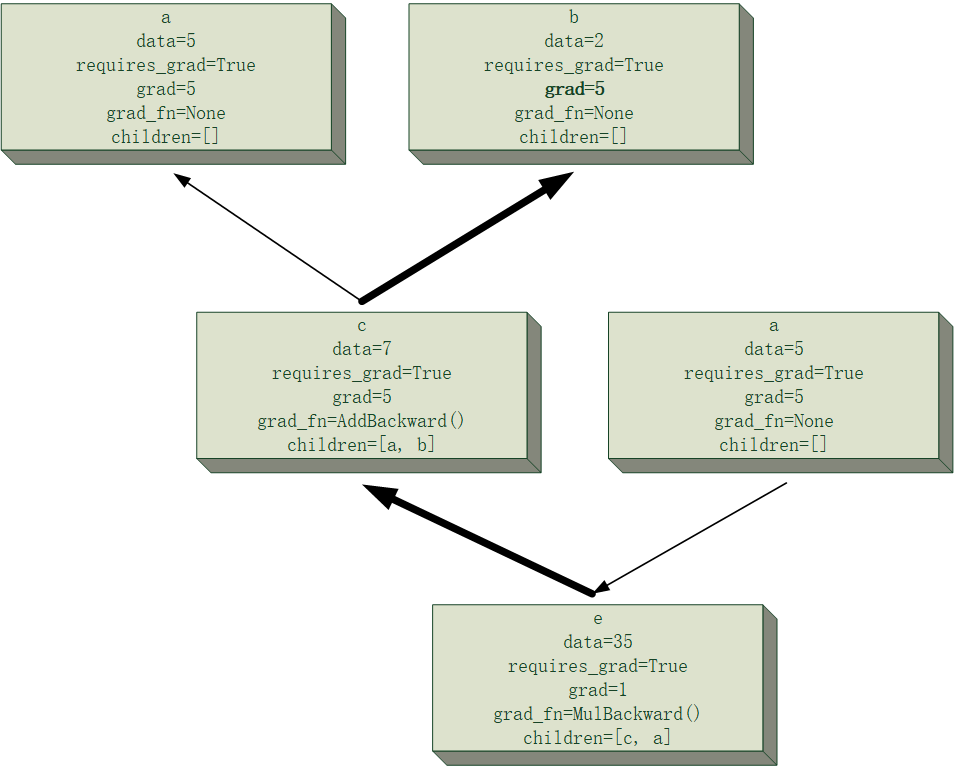
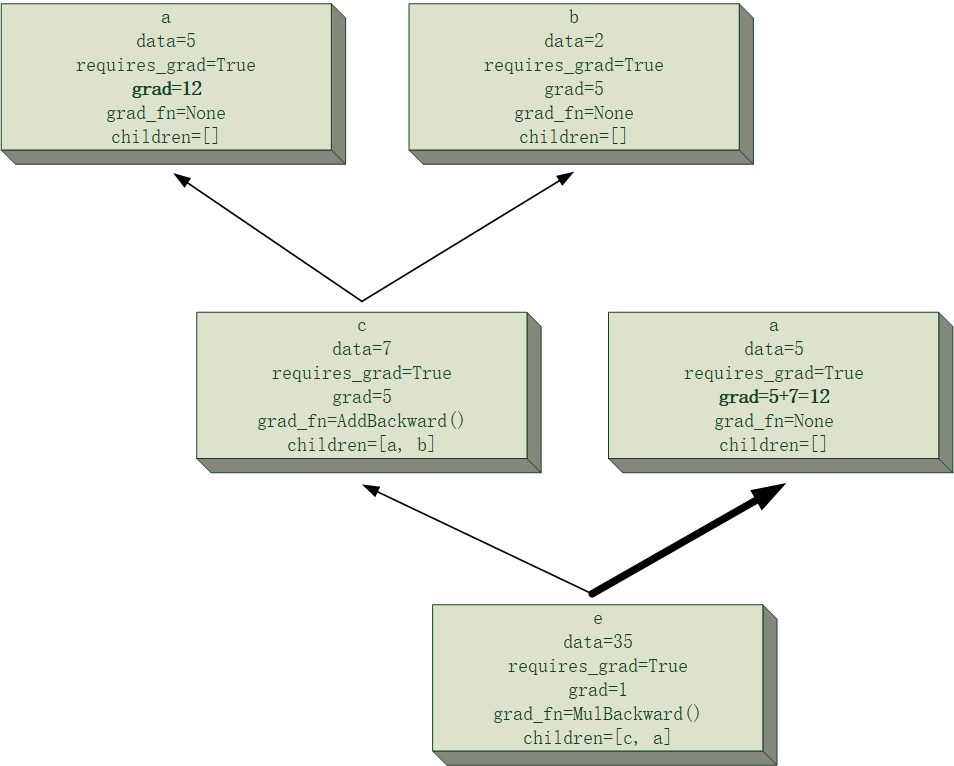
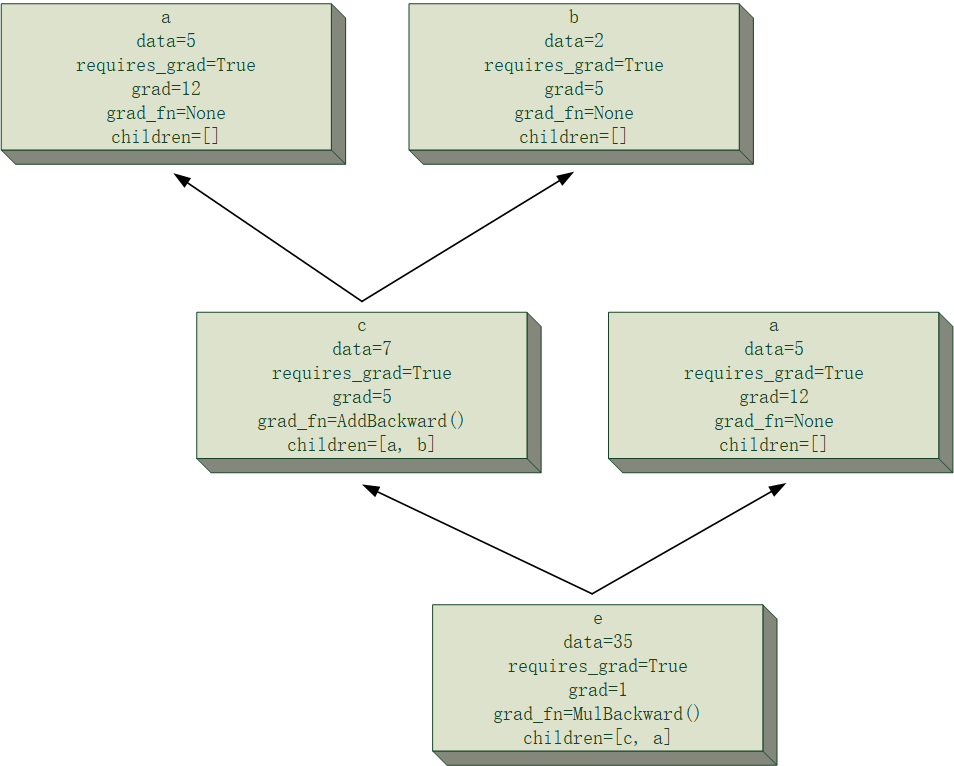
最后得到的结果为$\frac{\partial e}{\partial a}=12, \frac{\partial e}{\partial b}=5$,和自己口算的应该没差吧。
Tensor类涉及到的方法还有很多很多,文件有一千多行,没有办法面面俱到,但我认为主要就是这几个,其他的都比较易于理解,有兴趣的话可以自己去看一下我的源码。
其实我对这个Tensor类的写法是相当不满意的,感觉写的太冗杂了,而且设计结构的时候没有充分考虑清楚,各位可以自己去摸索一下计算图节点的定义方法,看看怎么样搞更合适。
该系列接下来的文章将开始进入正轨,也就是各种运算的梯度反传函数的写法(WTF?才进入正轨??)。梯度反传函数我写的非常乱七八糟,但至少能算对!这就已经让我很心满意足了。
- V me 50!
- Alipay is also ok~