手撸神经网络系列之——梯度反传函数具体怎么写?(三)
本文将介绍几种特殊张量运算的反向传播。
众所周知,神经网络中涉及到关于张量的运算不止于加减乘除,还有最大最小值运算等,与常规运算不同,有些特殊运算在数学上甚至是不可微的,但即便如此,我们仍然需要将梯度反传回去。
本系列全部代码见下面仓库:

如有算法或实现方式上的问题,请各位大佬轻喷+指正!
本文将介绍Swapaxes运算、Max运算的反向传播。其他特殊运算,就不再一一列举!(主要太懒了)
Swapaxes
与矩阵的转置类似,张量运算swapaxes的目的就是交换某两个轴,其定义为:
def swapaxes(self, axis1, axis2):
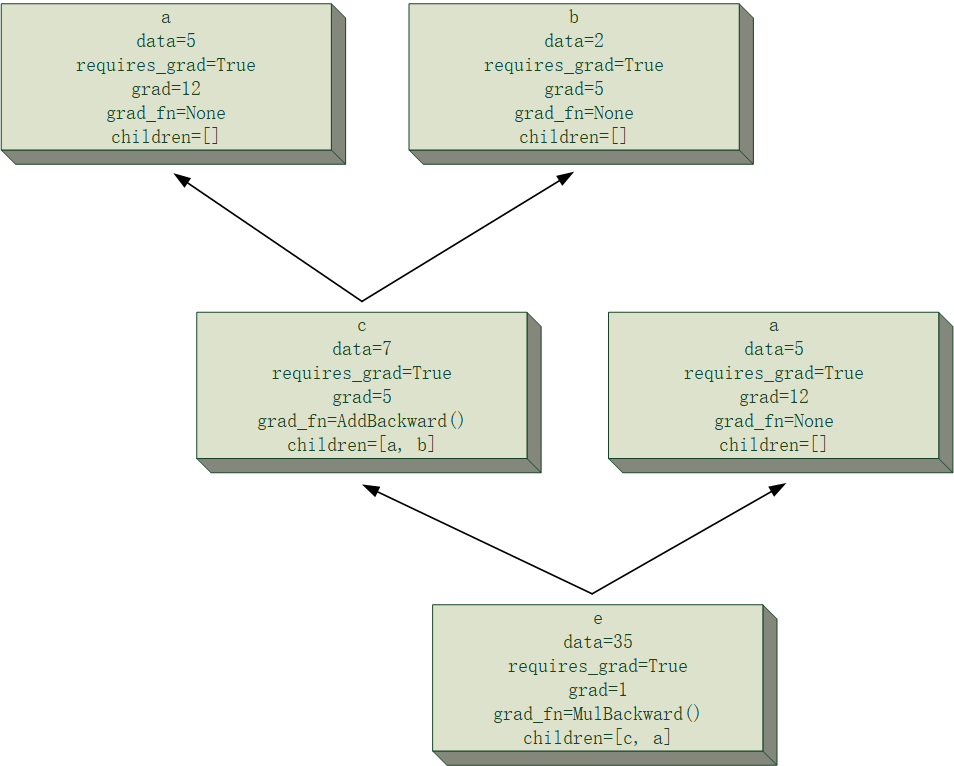
...axis1、axis2即为交换的两个轴的序号。稍微想一想容易知道,怎么换过去的就怎么换回来,反传回去的梯度应该就是把梯度的axis1、axis2轴交换一下。所以在正向传播时,我们就要把两个交换轴的序号记录在计算图里。
正向传播:
def swapaxes(self, axis1, axis2):
result = Tensor(self.data.swapaxes(axis1, axis2), dtype=self.dtype, requires_grad=self.requires_grad)
if result.grad_enable:
result.children = [(self, axis1, axis2)]
result.grad_fn = SwapaxesBackward()
return result反向传播:
class SwapaxesBackward(BackwardFcn):
def __init__(self):
super(SwapaxesBackward, self).__init__()
def calculate_grad(self, grad, children, place):
axis1, axis2 = children[0][1:]
return grad.swapaxes(axis1, axis2)是不是非常ez!还有很多其他运算,例如Transpose等,也需要记录一些额外的信息。另外,有一些运算虽然并不需要额外信息,但若提供了额外的信息,会对梯度计算有很大的帮助,例如大名鼎鼎的交叉熵函数,各位可以自己推导一下交叉熵函数的梯度,然后思考一下提供什么信息可以加快交叉熵函数梯度的计算。推导过程可以看我这篇文章。
Max
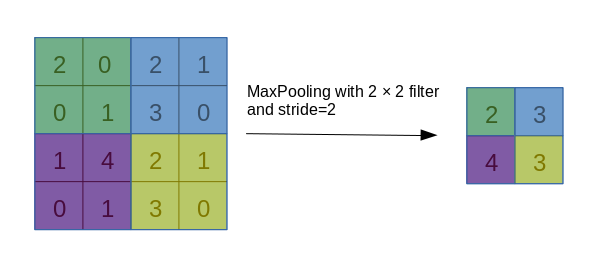
Max运算在数学上是一个分段的函数,和绝对值函数一样,在分段端点处不可微,在神经网络里经常遇到各种取最大值的运算,常见的例如MaxPooling。虽然它存在不可微点,但我们仍然有办法搞出一个形式上的梯度,并将其反传回去。
考虑以下$2\times 3$矩阵:
对其做max运算有三种情况:1、全局max;2、对每一行取max;3、对每一列取max。对于这些情况,我们的代码中均需要实现梯度反向传播。不过,在写梯度反传函数以前,需要先看一下梯度要怎么传。
第一种情况,对全局取max,得到的结果为6:
我们将梯度这个概念还原回最本质的东西,即当某一个量$x$发生微小的变化$\delta x$时,结果产生的变化$\delta y$与这个小改变量$\delta x$比值$\delta y / \delta x$的极限。在这个全局的max运算下,根据max的逻辑可知,对任何非最大值进行微小的改变,均不会影响到最终的结果;而当最大值所在的位置发生微小的改变时,结果也将产生等值的改变。综合上面的考虑,它的梯度就应该是长这样的:
后两种情况,其实可以统一为一种情况,即对某些轴取max(可以不止一个轴),这里通过对行取max的例子来研究一下规律。
首先需要改变一下说法,所谓对“行”取max,过程是固定矩阵的“行”进行遍历,在每一行中找出最大值,相当于在max运算中指定axis=1,而对“列”取max,同理相当于axis=0,但在高维张量的情况下,就没有行和列的概念了,故以后都将用遍历轴axis来说明。
类似地,同样容易得到梯度回传系数为
即,在两个最大值所处的位置上为1,其余为0。这也符合常人的理解。
还有一种特殊情况,即存在多个最大值的情况,例如:
这种情况我将其处理为多个最大值按相同权重均分梯度,得到的梯度回传系数如下:
综合以上考虑,我们就可以着手进行代码的实现了。这里我的思路是,将max运算得到的结果以及axis值存在计算图中,反向传播时调用这两个量,将max得到的结果通过复制自身的方式,扩展到与原张量相同。
回到这个例子:
可以先将max得到的结果$\begin{bmatrix}3 & 6\end{bmatrix}$经过以下两步变换:
- 根据axis的值添加维度,使结果成为keepdims=True的形式(对keepdims这个参数不太了解的童鞋可以先去了解一下)。
- 根据原张量的形状,在axis的方向上tile自身。
然后将扩展后的结果,与原张量进行比较:
最后沿着所有axis进行归一化(和为1):
处理的过程大概就是上面这样,细节可以看我的MaxBackward代码!对于Min和Mean运算,大体也差不多,故不再重复。
张量的特殊运算还有一大堆,但这里空白太小,我写不下。不过,相信看到这里,推导梯度并将其转换为代码实现对你而言应该不是什么大难题了!接下来的内容将围绕著名的卷积神经网络展开,重点讲解卷积运算的正向、反向传播,还会补充池化运算以及BN层的细节。
- V me 50!
- Alipay is also ok~