手撸神经网络系列之——卷积运算的正向传播(三)
前文介绍了一种卷积运算的骚操作——img2col,但仍不是十分满意,本文将介绍另一种卷积的骚操作——as_strided。
用as_strided结合tensordot函数,实现的卷积运算甚至不需要在Python中做for循环,达到了极致的简洁美。
本系列全部代码见下面仓库:

如有算法或实现方式上的问题,请各位大佬轻喷+指正!
本文很长,希望你忍一下。
一些你需要了解的前置知识
Numpy数组在内存中的存储
我们首先介绍numpy数组在内存里存储方式。
众所周知,numpy中的数据类型都有其对应的内存占用,例如int64与float64都会占用8个byte的内存空间,bool类型占用1个byte等。具体请移步官方文档进行查看。
除此以外,我们还需要知道numpy数组的元素在内存中的排列顺序。如果数组是一个向量:$[1, 2, 3, 4]$,那么自然是按从左到右的顺序连续存储在内存中;如果数组是一个矩阵:,这种情况下,数据会按从左到右、从上到下的顺序,连续存储在内存中,即存放顺序与向量$[1, 2, 3, 4]$是一样的;一般地,对于任意一个多维的数组,其中的数据在内存中的索引应该满足一个维度从外到内的遍历顺序,一个形状为(a1, a2, ..., an)的数组,在内存中的顺序相当于以下面的方式进行遍历的顺序:
for i_1 in range(a1):
for i_2 in range(a2):
...
for i_n in range(an):
array[i_1, i_2, ... i_n]值得一提的是,如果将一个数组进行flatten操作,得到的向量正是其元素在内存中的排列。
Numpy数组的Strides属性
接下来,就可以引入numpy数组的strides(跨度)概念,官方对其的定义如下:
Tuple of bytes to step in each dimension when traversing an array.
大概意思就是,从数组上的某个位置出发,沿着某个坐标轴移动到下一个位置,必须跳过的内存中的字节数。下面以一个简单的例子来说明这个概念:
考虑以下数据类型为int64的numpy数组:
它的元素在内存中的顺序是:$[1, 2, 3, 4, 5, 6]$,共占用$6\times 8 = 48$个byte。这个矩阵有两个坐标轴,分别是0轴和1轴(注意:该矩阵的形状为(2, 3),它的0轴表示长度为2的轴,实际上是纵向的,而1轴则是横向的)。现在假设我们处于元素1的位置上,要想沿着0轴移动到下一个位置——4,在内存中需要跳过多少个byte呢?显而易见,1和4在内存中共隔了两个元素:2、3。1想要到达4,必须依次到达2、3、4,故1沿着0轴移动到下一个位置4需要跳过$3\times 8 = 24$个byte。
同理,从元素1的位置上沿着1轴到达下一个位置——2,只需要跳过8个byte,因为它们在内存上是相邻的。
所以我们说,这个矩阵的strides属性为(24, 8)。
在numpy中,我们不需要手动去计算strides属性,因为数组自身就带了这个attribute,直接调用即可。
as_strided函数
有了strides的概念,我们终于可以引入高效卷积运算的大杀器——as_strided函数,我们可以通过下面的方式导入它:
from numpy.lib.stride_tricks import as_strided真是深藏不露…
我们来看其官方注释:
def as_strided(x, shape=None, strides=None, subok=False, writeable=True):
"""
Create a view into the array with the given shape and strides.
.. warning:: This function has to be used with extreme care, see notes.
Parameters
----------
x : ndarray
Array to create a new.
shape : sequence of int, optional
The shape of the new array. Defaults to ``x.shape``.
strides : sequence of int, optional
The strides of the new array. Defaults to ``x.strides``.
subok : bool, optional
.. versionadded:: 1.10warning意味着你想调用这个函数一定要非常小心,因为它是直接操作内存的,稍有不慎就会出现一些溢出错误,而直接操作内存也是其效率极高的原因所在。
首先开门见山地进行说明,这个函数的作用是通过在一个给定数组中取值,来生成一个新的数组,至于要如何取值,且看下文分解。
这个函数需要提供的参数共有5个,然而我们一般只需要提供前3个参数就好了,下面对前3个参数进行解释。
- x:给定的数组,函数将会在这个数组中进行取值,来生成结果。
- shape:表示输出数组的形状,这个也容易理解,你要生成新数组总得知道它的形状吧。
- strides:与前面的strides的意义略有不同,该参数描述了从给定数组x中取数的规则。其意义是,从新数组的某个位置出发,沿着新数组的某个坐标轴移动到下一个位置,需要跳过的给定原数组x所占用内存中的字节数。
相信看了如上对strides参数的解释,你一定是一头雾水。下面还是以一个例子来解释:
依然考虑数据类型为int64的矩阵:
我们用它来生成另一个$2\times 3$的矩阵,并且指定参数strides=(16, 8),来手动操作一下这个过程。
首先,新数组的第一个元素,对应的也是原数组的第一个元素,即为1。接下来,我们先沿着新数组的1轴走一步,看看这个位置上应该是多少。strides参数告诉我们,沿着新数组的1轴走一步,需要跨过原数组内存上的8个byte,而原数组元素在内存上的顺序是$[1, 2, 3, 4, 5, 6]$,从1的位置出发,跨越8个byte得到的数是2,因此,新数组的$[0, 1]$位置上的元素就是2。同理,从新数组的$[0, 1]$位置出发沿着1轴再走一步,也需要跨过原数组内存上的8个byte,因此我们得到新数组$[0, 2]$位置上的元素是3。
现在再来看新数组的0轴方向,我们依然从新数组的$[0, 0]$位置出发,这回沿着0轴走一步,strides参数告诉我们,沿着新数组的0轴走一步,需要跨过原数组内存上的16个byte,而对原数组而言,元素1往后16个byte是元素3,因此,新数组$[1, 0]$位置上的元素是3。剩下的其他位置也是同理。
据此,我们已经推导出了整个新数组的真面目:
相信读到这里,你大概确乎一定已经知道了as_strides的规则和用法了,那么它在卷积运算里有什么用呢?且看下文分解。
新的卷积方法
依然以下面卷积过程为例子:
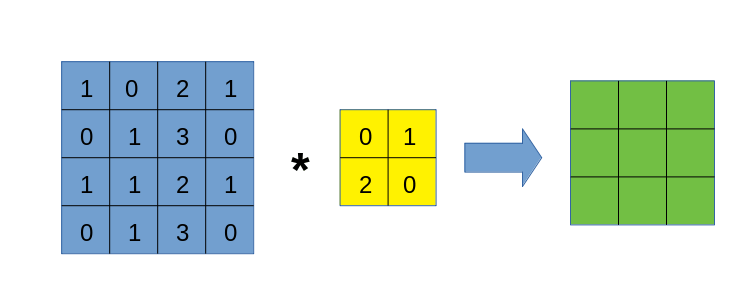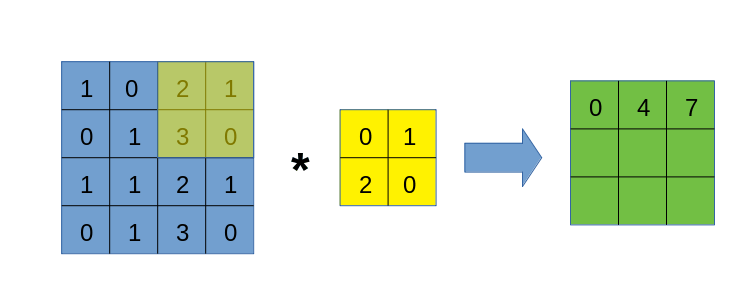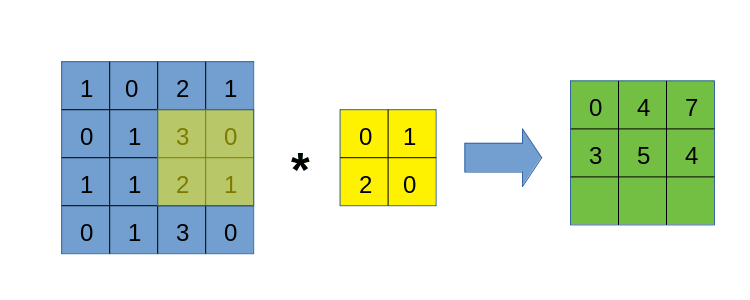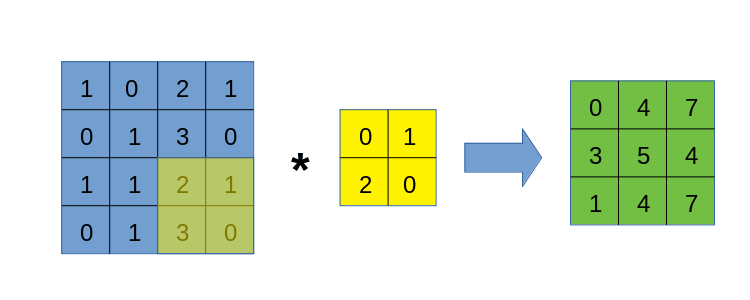
与img2col类似,我们也要将卷积核遍历过程中的每一块数据区域依次拿出来,但区别在于,我们不破坏数据自身的二维结构,也不将区域拉直处理,而是一个以下的过程:
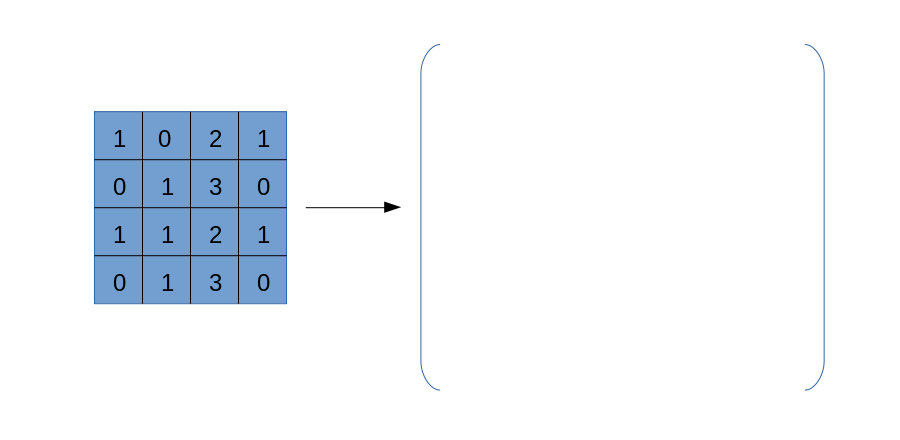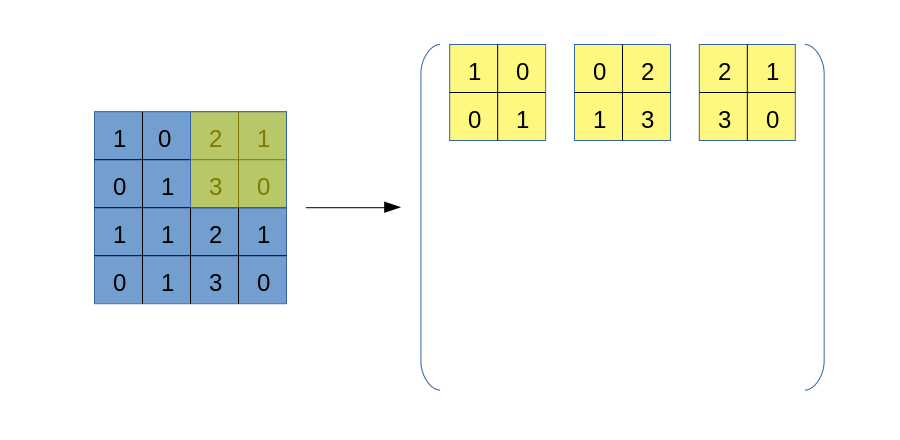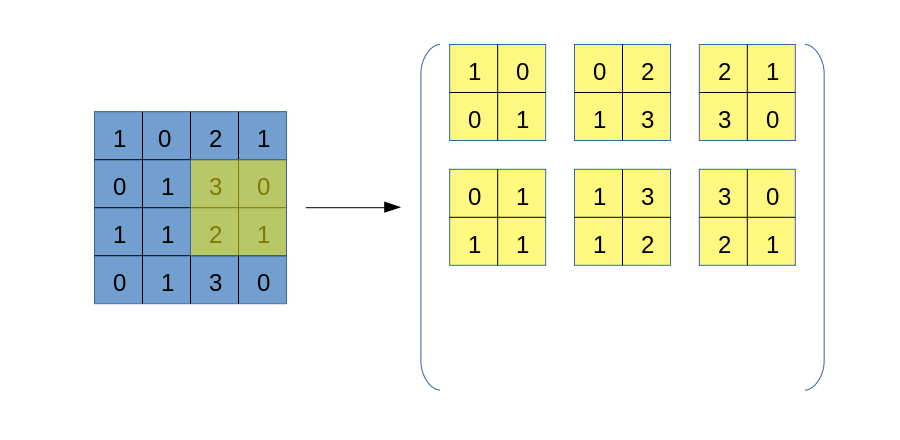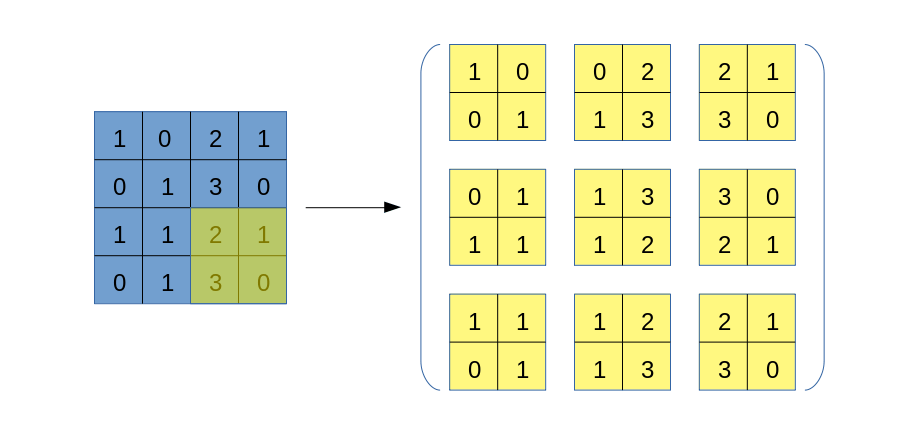
这个过程应该比较容易理解,但需要注意的是,上图右侧得到的张量,其形状并非是(6, 6),而是(3, 3, 2, 2)!虽然不知道大家是否可以理解这个表示方式,但我希望可以,它的外层是一个$3\times 3$矩阵,其每一个元素都是一个$2\times 2$矩阵。
这样一种分割,看上去不是很自然,但这恰好是as_strided函数可以胜任的工作。接下来,我们需要把这个过程用as_strided函数写出来。
import numpy as np
from numpy.lib.stride_tricks import as_strided
x = np.array([[1, 0, 2, 1],
[0, 1, 3, 0],
[1, 1, 2, 1],
[0, 1, 3, 0]])
output = as_strided(x, shape=?, strides=?)应该如何指定shape和strides参数,才能让output得到上面分割后的张量?首先容易得出shape是(3, 3, 2, 2),因为它代表我期望得到的张量的形状。接下来我们来分析strides参数。
输出张量共有四个轴,分别记为0、1、2、3轴,我们先分析最后的3轴,从输出张量的初始位置出发,沿着3轴移动一步的过程相当于下图:
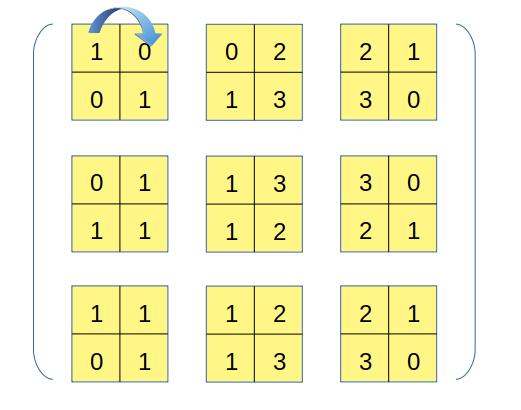
这一步对应到原数组上,相当于沿着1轴移了一步,注意到原数组的数据类型为int64,因此这一步移动对应的内存移动量为8个byte,相当于原数组的strides[1],故3轴对应的strides参数值为8。
接下来分析2轴的情况,从输出张量的初始位置出发,沿着2轴移动一步的过程相当于下图:
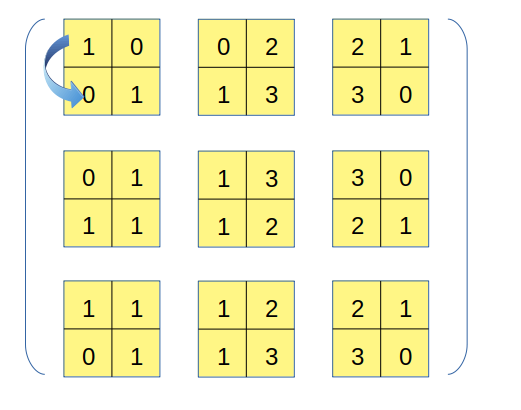
这一步对应到原数组上,相当于沿着0轴移了一步,因此这一步移动对应的内存移动量原数组的strides[0]=32个byte,故2轴对应的strides参数值为32。
然后分析1轴,从输出张量的初始位置出发,沿着1轴移动一步的过程相当于下图:
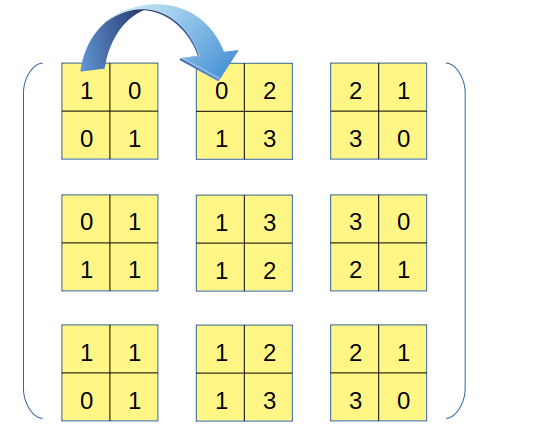
这一步虽然看上去跨的比较远,但在原数组上,仅仅只是沿1轴移了一步,因为目标位置上的元素0,在原数组中的位置恰好就在1右边。因此这一步移动对应的内存移动量为8个byte,相当于原数组的strides[1],故1轴对应的strides参数值也为8。
最后分析0轴,从输出张量的初始位置出发,沿着0轴移动一步的过程相当于下图:
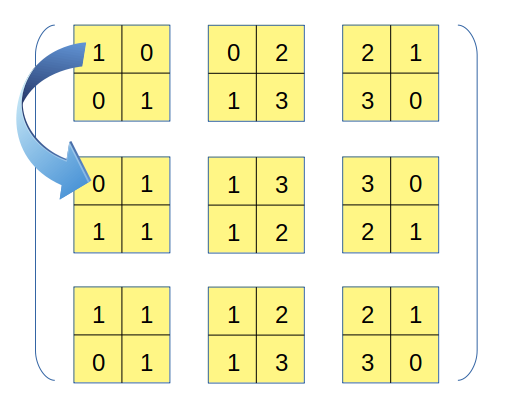
这一步移动,在原数组上相对于沿着0轴移了一步,因此这一步移动对应的内存移动量相当于原数组的strides[0]=32个byte,故0轴对应的strides参数值也为32。
综合以上分析,strides应为(32, 8, 32, 8)。
import numpy as np
from numpy.lib.stride_tricks import as_strided
x = np.array([[1, 0, 2, 1],
[0, 1, 3, 0],
[1, 1, 2, 1],
[0, 1, 3, 0]])
output = as_strided(x, shape=(3, 3, 2, 2), strides=(32, 8, 32, 8))这样写代码就可以把output算出来了,各位可以跑一下看看结果对不对。它的输出结果不像图片中的那样直观:
>>> output
array([[[[1, 0],
[0, 1]],
[[0, 2],
[1, 3]],
[[2, 1],
[3, 0]]],
[[[0, 1],
[1, 1]],
[[1, 3],
[1, 2]],
[[3, 0],
[2, 1]]],
[[[1, 1],
[0, 1]],
[[1, 2],
[1, 3]],
[[2, 1],
[3, 0]]]])得到了output以后,如何用它来算卷积呢?这时又要请出另一个经常被大家忽略的函数:tensordot。
tensordot函数
tensordot这个函数,看名字好像是张量点积的意思,事实上它确实也正是做张量点积运算的,它的强大之处在于可以分别指定对两个张量的哪些轴进行点积运算。官方注释如下:
def tensordot(a, b, axes=2):
"""
Compute tensor dot product along specified axes.
Given two tensors, `a` and `b`, and an array_like object containing
two array_like objects, ``(a_axes, b_axes)``, sum the products of
`a`'s and `b`'s elements (components) over the axes specified by
``a_axes`` and ``b_axes``. The third argument can be a single non-negative
integer_like scalar, ``N``; if it is such, then the last ``N`` dimensions
of `a` and the first ``N`` dimensions of `b` are summed over.
Parameters
----------
a, b : array_like
Tensors to "dot".
axes : int or (2,) array_like
* integer_like
If an int N, sum over the last N axes of `a` and the first N axes
of `b` in order. The sizes of the corresponding axes must match.
* (2,) array_like
Or, a list of axes to be summed over, first sequence applying to `a`,
second to `b`. Both elements array_like must be of the same length.
Returns
-------
output : ndarray
The tensor dot product of the input.参数非常简单,就是简单粗暴两个张量,以及一个坐标轴参数。我们重点讲axes参数的作用。官方注释对axes参数的描述分了两种情况,我们针对第二种来说明。
axes参数是一个list,长度为2,其两个元素分别表示了两个张量的求和轴。
在张量内积运算中,有两个概念,是我自己编出来的,一是求和轴(或固定轴),二是遍历轴,我们以最常见的矩阵乘法为例子,来说明这两个概念。
这两个矩阵的乘积可以看成如下顺序过程:
- 左矩阵的第一行与右矩阵的第一列做内积
- 左矩阵的第一行与右矩阵的第二列做内积
- 左矩阵的第二行与右矩阵的第一列做内积
- 左矩阵的第二行与右矩阵的第二列做内积
这里,我们发现,对左矩阵而言,其在沿着列方向,遍历所有的行;对右矩阵而言,其在沿着行方向,遍历所有的列。每一次取到左矩阵的某一行与右矩阵的某一列,都将它们进行点积运算。
这里我们就说,左矩阵的求和轴是行,对应1轴,遍历轴是列,对应0轴;同理,右矩阵的求和轴是0轴,遍历轴是1轴。我们就要在tensordot函数中指定axes参数为[1, 0]
用tensordot的写法如下:
a = np.array([[1, 2, 3], [4, 5, 6]])
b = np.array([[2, 3],[4, 5],[6, 7]])
result = np.tensordot(a, b, axes=[1, 0])容易验证,该结果与直接a.dot(b)等价,可以说,tensordot就是dot函数的推广。另外,经过上面的演示,能够发现两个张量在各自求和轴上的长度一定是两两相等的。
tensordot在卷积中的应用
注意到,卷积运算好像也有类似于点积的操作——将每一块数据区域和卷积核进行的先乘后求和的运算就是一种点积,因此我们可以用tensordot来做卷积。
这就是前面要把原矩阵进行奇奇怪怪的分割的原因了!依然是前面的例子,现在分割得到的张量,形状为(3, 3, 2, 2),卷积核的形状为(2, 2),不靠想象,直接根据这两个张量的形状,就可以迅速判断tensordot的axes参数值——[(2, 3), (0, 1)]
import numpy as np
from numpy.lib.stride_tricks import as_strided
x = np.array([[1, 0, 2, 1],
[0, 1, 3, 0],
[1, 1, 2, 1],
[0, 1, 3, 0]])
output = as_strided(x, shape=(3, 3, 2, 2), strides=(32, 8, 32, 8))
kernel = np.array([[0, 1],
[2, 0]])
result = np.tensordot(output, kernel, axes=((2, 3), (0, 1)))>>> result
array([[0, 4, 7],
[3, 5, 4],
[1, 4, 7]])够不够简单粗暴!这种方法竟然一句显式的for循环都没用到。不过,上面这个例子太简单了,我们真正要用到的卷积,是四维卷积四维,但方法依然如出一辙,只是稍微复杂了一些。
完整的卷积运算
下面给出一个通用的split函数:
def split_by_strides(x: np.ndarray, kernel_size, stride=(1, 1)):
"""
将张量按卷积核尺寸与步长进行分割
:param x: 被卷积的张量
:param kernel_size: 卷积核的长宽
:param stride: 步长
:return: y: 按卷积步骤展开后的矩阵
"""
*bc, h, w = x.shape
out_H, out_W = (h - kernel_size[0]) // stride[0] + 1, (w - kernel_size[1]) // stride[1] + 1
shape = (*bc, out_H, out_W, kernel_size[0], kernel_size[1])
strides = (*x.strides[:-2], x.strides[-2] * stride[0],
x.strides[-1] * stride[1], *x.strides[-2:])
y = as_strided(x, shape, strides=strides)
return y其实就是通过代码计算了as_strided函数需要的参数,首先确定目标的shape,思考一下就知道,前面例子里的形状(3, 3, 2, 2)的前两个3其实是卷积结果的H和W,后两个2其实是卷积核的h和w,这里的shape相比于前面的例子,要多两个维度,即B(Batchsize)和C(Channels),shape现在是个六元的tuple,其对应的strides参数应该也是六元。现在我们来确定strides,strides参数的最后两个位置,一定是与原张量最后两个轴的strides相同,因为它们对应的是同一个数据分块中,两个方向上的移动;倒数第三个位置,对应的是下面这个图的情况:
图中的例子里,仅仅是在原矩阵上跨越了一个元素的距离,但这其实是卷积步长为1时的特殊情形,一般的情形,该值是卷积横向的步长stride[1]$\times$原矩阵末轴对应的stride,故倒数第三个位置应该为x.strides[-1] * stride[1]。
倒数第四个位置,对应的情况则是:
与前面一个情况类似,需要考虑卷积纵向的步长stride[0],结果为x.strides[-2] * stride[0]。
现在,strides参数已经确定了最后的四个位置,只差前两个位置了,这两个位置其实更容易想到,因为第0个位置,对应的维度是B,在这个维度上移动一步需要跨越的内存空间,肯定就是两个相邻数据之间的跨越空间,故一定等于x.strides[0];第1个位置对应维度是C,在这个维度上移动一步需要跨越的内存空间,就相当于同一个数据的两个相邻通道之间的跨越空间,故一定等于x.strides[1]。我在代码中,写成了更一般化的形式:*x.strides[:-2],当x是四维张量时,它就相当于(x.strides[0], x.strides[1])。
对于tensordot函数应该指定哪些轴作为求和轴,其实只要看两个张量的哪几个轴在进行内积运算。我们知道,卷积中的内积操作,发生在每一个数据区域和每一个卷积核之间,每一块数据区域包含的维度是C(Channels)、h(卷积核的高度)、w(卷积核的宽度),每个卷积核的维度也是C、h、w。而我们经过split后的数据,它的维度是六维(B, C, out_H, out_W, h, w),卷积核的维度则是(out_C, C, h, w),那么数据对应的求和轴自然是(1, 4, 5)轴,卷积核对应的求和轴则是(1, 2, 3)轴。我们将两个张量形状里的(C, h, w)前后“约掉”,剩下的拼起来,就能得到输出结果的形状(B, out_H, out_W, out_C),但我们不希望Channels维度放在最后,希望它换到第1个轴的位置,故我们还需要做一个transpose操作:transpose((0, 3, 1, 2)),即可得到形状为(B, out_C, out_H, out_W)的张量,这正是我们需要的卷积结果!
全部的卷积过程,仅化为以下两步:
split = split_by_strides(data, kernels.shape[-2:], stride=stride)
output = np.tensordot(split, kernels, axes=[(1, 4, 5), (1, 2, 3)]).transpose((0, 3, 1, 2))本文相对有点烧脑,需要各位好好琢磨琢磨as_strided和tensordot这两个函数的用法以及卷积运算的细节。至此,卷积运算的正向传播过程告一段落,后面的文章将进入卷积运算的反向传播。
- V me 50!
- Alipay is also ok~