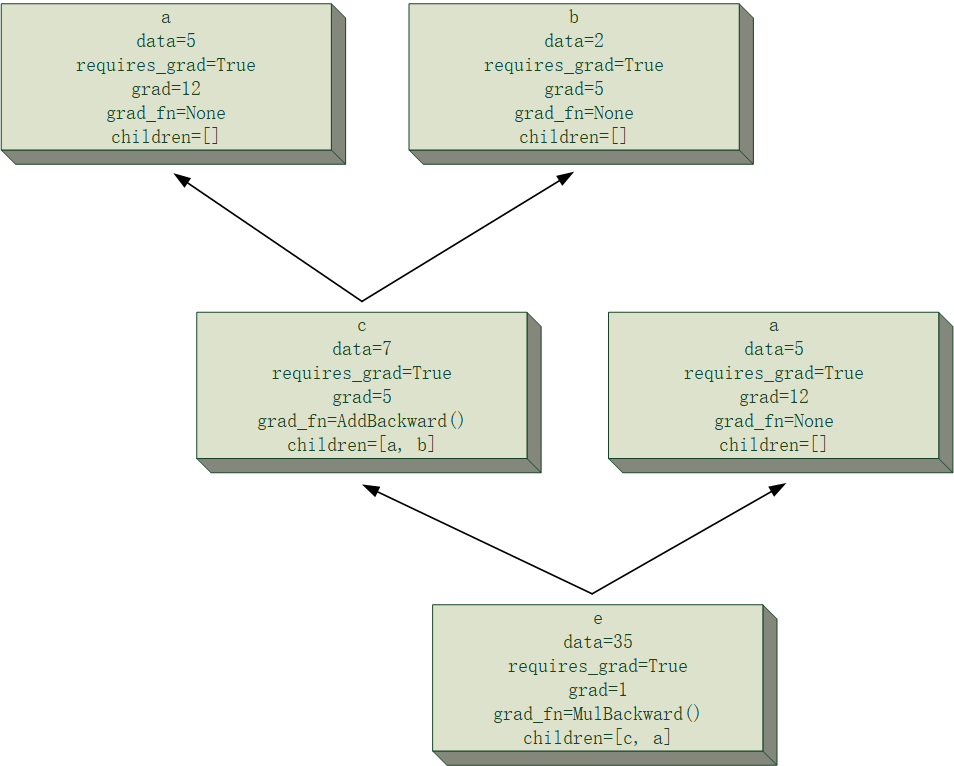
手撸神经网络系列之——训练模型(完结篇)
本文是此系列的完结篇,我们将用自己实现的神经网络来训练一个识别手写数字的模型。训练代码包含一些我前面没有提到的东西,例如数据变换函数等,不过这些都并非本系列的重点,实现起来也很简单粗暴,故不再细说!
本系列全部代码见下面仓库:

如有算法或实现方式上的问题,请各位大佬轻喷+指正!
本文的内容对于深度学习领域的学习者而言应该是非常熟悉的基本操作,所以我基本只贴代码了,望谅解。
注:本文模型结构与上图并不符,上图只是用来充个数的
我们先给出数据载入函数与数据类:
def load_mnist(img_path, label_path):
with open(label_path, 'rb') as label:
struct.unpack('>II', label.read(8))
labels = np.fromfile(label, dtype=np.uint8)
with open(img_path, 'rb') as img:
_, num, rows, cols = struct.unpack('>IIII', img.read(16))
images = np.fromfile(img, dtype=np.uint8).reshape(num, rows, cols)
return images, labels
class MNISTDataset(Dataset):
def __init__(self, data_path, label_path):
super(MNISTDataset, self).__init__()
self.data, self.label = load_mnist(data_path, label_path)
def __len__(self):
return len(self.label)
def __getitem__(self, item):
return trans(self.data[item]), nptorch.tensor(self.label[item])数据怎么读的可以不管,你只要知道它是用来读数据的就行了。定义了上述内容后,我们就可以以下面的方式读取MNIST数据:
train_set = MNISTDataset('mnist/MNIST/raw/train-images-idx3-ubyte', 'mnist/MNIST/raw/train-labels-idx1-ubyte')
test_set = MNISTDataset('mnist/MNIST/raw/t10k-images-idx3-ubyte', 'mnist/MNIST/raw/t10k-labels-idx1-ubyte')
train_loader = DataLoader(train_set, batch_size=64)
test_loader = DataLoader(test_set, batch_size=128, drop_last=True)这些代码里的Dataset和DataLoader类也都是我自己定义的class,它们位于项目中的utils/data/目录下,比较容易实现。
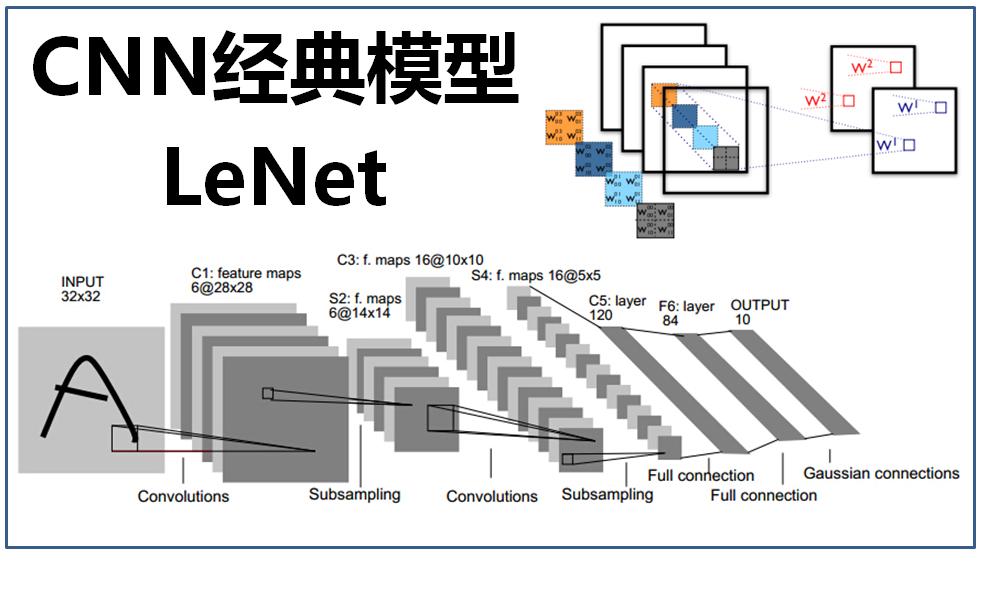
接下来贴出LeNet模型的代码:
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, 3, dilation=(1, 1)),
nn.MaxPool2d(2),
nn.BatchNorm2d(16),
nn.ReLU(inplace=True),
nn.Conv2d(16, 32, 3, dilation=(1, 1)),
nn.MaxPool2d(2),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
)
self.layer2 = nn.Sequential(
nn.Linear(32 * 25, 128),
nn.BatchNorm1d(128),
nn.ReLU(inplace=True),
nn.Linear(128, 64),
nn.BatchNorm1d(64),
nn.ReLU(inplace=True),
nn.Linear(64, 10)
)
def forward(self, x: nptorch.Tensor):
x = self.layer1(x)
x = x.reshape(x.shape[0], -1)
x = self.layer2(x)
return x这也是我刚入门PyTorch,完全不懂神经网络时,照着示例抄的第一个神经网络,我将其结构搬了过来,如今再看,网络中的模块都如透明的一般呈现在眼前,完全是不同的感觉。
下面生成模型实例、优化器以及交叉熵损失函数:
model = LeNet()
optimizer = SGD(model.parameters(), lr=1e-1, momentum=0.7)
loss_fcn = nn.CrossEntropyLoss()然后我们就可以开始训练了!
for i in tqdm(range(5)):
count = 0
for d, lb in train_loader:
model.train()
count += len(d)
print(count)
y_hat = model(d)
loss = loss_fcn(y_hat, lb)
loss.backward()
optimizer.step()
model.eval()
with nptorch.no_grad():
p = model(d).argmax(-1)
print(f'优化后的准确比率:{(p == lb).float().sum().item() / len(d)}')
optimizer.zero_grad()为节省时间,我这里训练了5个epoch,同时为了观察训练效果,每次优化以后,再重新测一遍当前batch的准确率。
最后,我们对训练好的模型进行测试:
print(f'测试集准确率{test_model(model, test_loader)}')
print(f'训练集准确率{test_model(model, train_loader)}')因为懒得等它跑完,我这里只录了一部分屏,在测试时,用了以前训练好的模型进行测试。
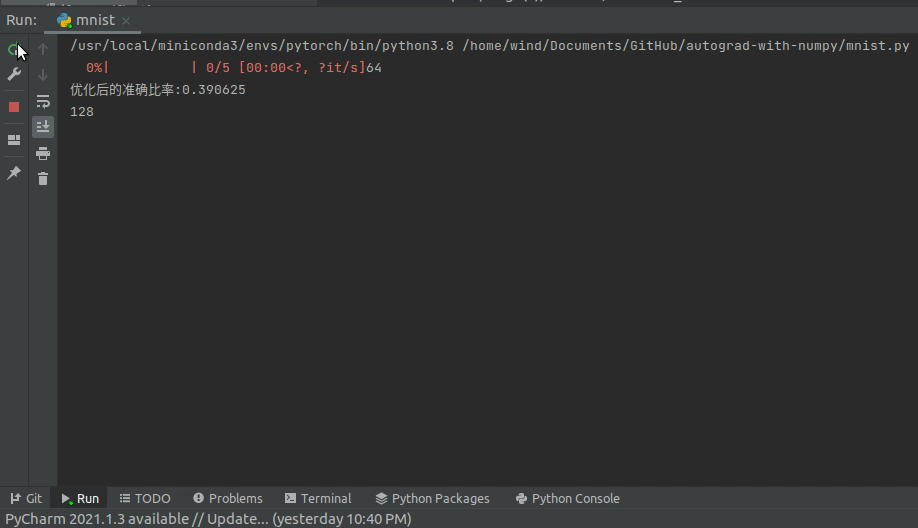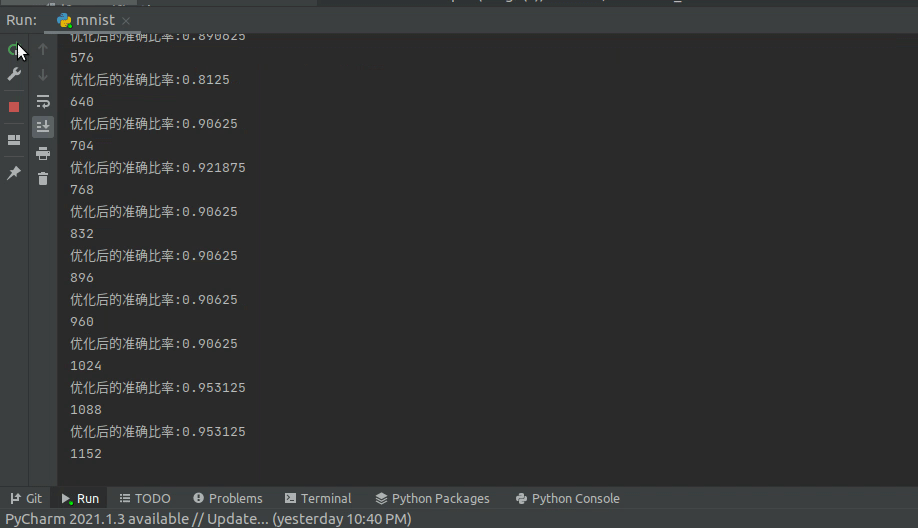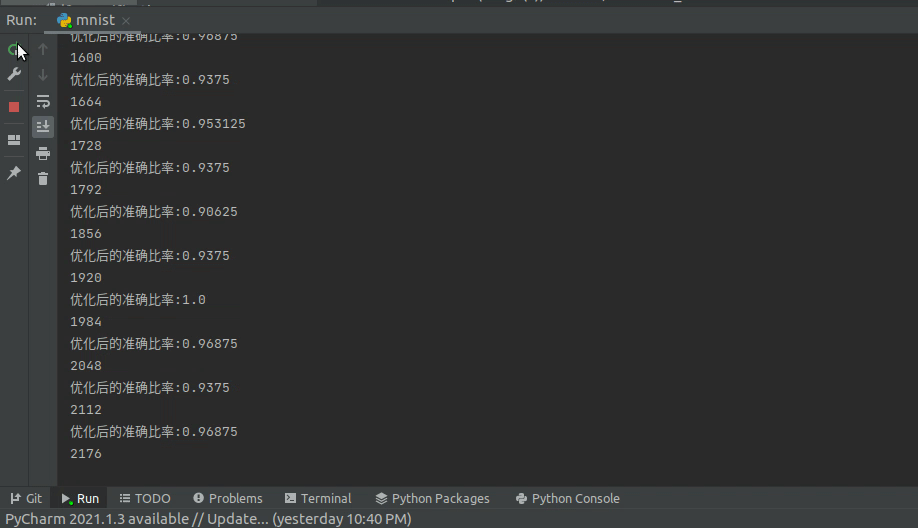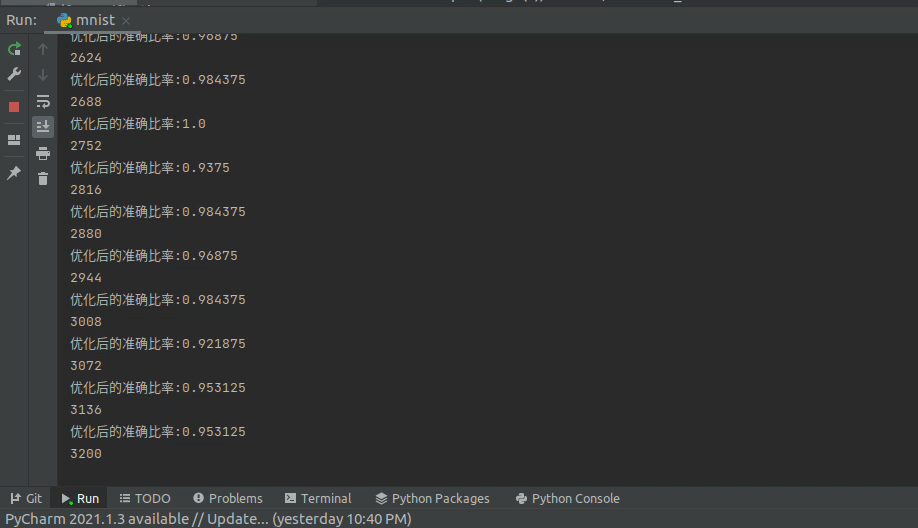
按这种速度跑一轮,大概是在5分钟左右,我的CPU型号是Intel i7-9750H,感觉已经很快了。
下面是测试结果:
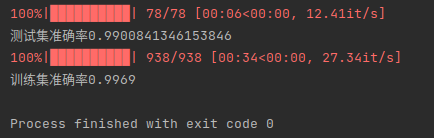
证明我们自己手写的神经网络确实work了,而且运行的非常完美!撒花!
在系列的最后,我必须感谢一路看到这里的你,但事实上,连续水了十五篇文章也没能把内容讲完整,不过,还是希望这个系列多多少少能带给你一些有用没用的知识。由于代码中涉及到反向传播的部分写的相当不优雅,若你在阅读过程中有任何疑问或是更优雅的反向传播实现,欢迎在下方留言或直接联系我。
- V me 50!
- Alipay is also ok~