Python实现12306购票(一)
12306号称反爬最强的网站,因此我小试了一下,花了几天时间,实现了脚本购票,并做了一个简单的cmd客户端。
本项目只是实现了通过发送数据包请求来实现购票,并未优化抢票流程、速度,仅供娱乐与学习。
从本文开始,将陆续分享几篇爬12306网站的经验和思路。首先,我并没有用到诸如selenium这类可以快速简化问题但运行速度极慢的模拟浏览器爬虫,而是用了requests库的无头请求方式。BTW,本文只分享思路,而不会涉及很多代码,若想查看完整代码,可访问下面仓库:

本文将分享其中最容易实现的功能:查询票务信息
本文相关代码见此文件
众所周知,即使你没有登录,也可以在12306网站上查询票务信息,并且在爬取过程中需要注意的地方并不多,因此我觉得这个功能是最容易实现的。
分析查票请求
首先,打开12306查票主页面https://kyfw.12306.cn/otn/leftTicket/init,进行一次查票,查票之前,通过浏览器开发者工具进行抓包,容易抓到一条类似这样的请求:https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date=xxxxxx...
把该请求详细写出来如下:
GET https://kyfw.12306.cn/otn/leftTicket/query
参数:
| 参数 | 说明 |
|---|---|
| leftTicketDTO.train_date | 日期(%Y-%m-%d格式) |
| leftTicketDTO.from_station | 出发站编号 |
| leftTicketDTO.to_station | 到达站编号 |
| purpose_codes | 固定为“ADULT” |
通常我们都选择成人票来进行搜索,故最后一个参数固定为ADULT,如果搜学生票,则需改成0X00
请求的response是一个json类型的数据包,从其中就可以拿到车票的信息了。
车站编号信息
为了生成请求参数,我们还需要找到这些站点编号是哪里来的,重新访问查票网页,注意到一条名为station_name.js?station_version=xxxx的请求,点进去一看,果然其包含了所有站点名以及编号的对应,我们请求该文件,然后用正则匹配把站点一一匹配出来,即可获取一个站点—编号一一对应的字典。
GET https://kyfw.12306.cn/otn/resources/js/framework/station_name.js
正则匹配处理代码:
def _get_station_info(self):
r = self.sess.get(self.station_info_url)
info = re.findall('([\u4e00-\u9fa5]+)\|([A-Z]+)', r.text)
return dict(info)接下来,似乎就可以愉快的进行查票了!
构造查票请求
但是当我精心构造完GET请求数据包,用requests发起请求时,却得到了一个奇怪的响应,它是一个html响应,而不是我们前面抓到的json类型数据。
难道是因为请求头不对被识别出来了?于是我加上了User-Agent、Host、Referer、Origin这四个请求头参数,再一次发起请求,这回居然拿到一个404响应。我:???
看来应该是Cookie的原因了,为了快速拿到Cookie,我用前面建立的Session对https://kyfw.12306.cn/otn/leftTicket/init即查票主页面进行请求,这样session即可获取到站点的Cookie,然后再用这个session进行查票。用这个思路一尝试,果然就成功了。
后来我发现,12306的票务信息API经常会发生改变,一会是/otn/leftTicket/query,一会是/otn/leftTicket/queryT,过两天又变成了/otn/leftTicket/queryY,这样老改代码也不是个办法,总得给他自动化一下,经过我的寻找,发现这个API是藏在前面的查票页面的网页中的:
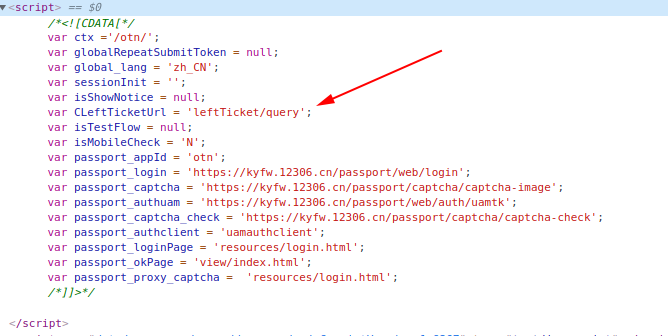
这样就非常的舒适了,前面正好需要对查票主页面进行一次没什么意义的GET请求来获取Cookie,现在正好可以把请求利用起来,可以用以下正则表达式把我们需要的内容匹配出来:
r = self.sess.get('https://kyfw.12306.cn/otn/leftTicket/init')
query_path = re.search('CLeftTicketUrl = \'(.+)\'', r.text).groups()[0]解析车票数据
接下来,我们只需对拿到的json数据(如下图)进行分析,看看内容是啥样的即可。

下面取出一条内容:
4YiGZGyS45ITAXtZ9oM45%2Fo7G22plhxiYt6nb7giDW88jJPYHX8GAtu1nchaIfvirs5LcTPhbZkB%0AHL7%2BCQGbEfc4i4gNlHuaHNkxY3qwh21IEhJC8YXOt%2BwZx4sWhMpNkE8xnf8BsRVeQSOSEwg4unbV%0A9di7k%2BkNkUhVFY6eNNPMwQ8wXZLim9LndM%2F3fr3maEiS6eAw5AMjJixQd0yFBkvpPimAHVZremLN%0A1b9pUhN6qwKCsFQtrFiWTLaAwH1K2GzphWMl7wDhawfd7TtB6ZVJWOYjInL3fz9eLZ2BREeOYIgG%0ATVOJVfsOy4KoDDEl|预订|40000K11080H|K1105|NFF|SNH|HFH|SNH|03:32|12:40|09:08|Y|eyz3JL6Yiyf7NIlRRnbbW7ueaEK5dgdbxSVSs1rc7O5KCp1%2Ff8wvYZS%2BN0I%3D|20211018|3|F2|10|16|1|0||||无|||无||无|有|||||403010W0|4311|0|1||4023300000301520000010086000211008603000|0|||||1|#0#0|
emmmmm….好像有点乱七八糟,前面一大串似乎是加密了的什么信息(先打个mark,这个东西在以后会用到),但好在后面逐渐出现人话,于是,可以将后面的内容与信息做一下对应,就可以把票的信息解析出来了。
这里的解析代码见文件中的_parse_ticket_info函数
如此一来,我们就顺利拿到了票务信息数据,但当前我们还没有实现登录,拿到了信息之后只能看看,啥都做不了,下篇文章将分享一下登录功能的实现,共实现了二维码扫码登录和账号密码(需手机验证码)登录两种方法,滑块登录的前端加密过于复杂,有点超出我的能力范围了。。。以后有空再研究。
- V me 50!
- Alipay is also ok~