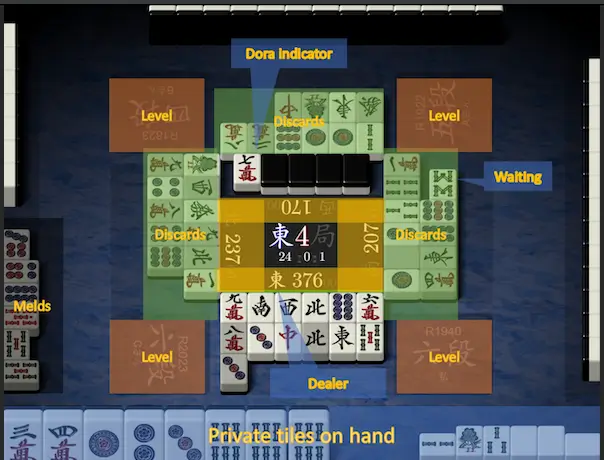
从零开始的麻将AI论文复现(一)
这篇文章,我来介绍一下我对麻将局面信息的特征编码方法。
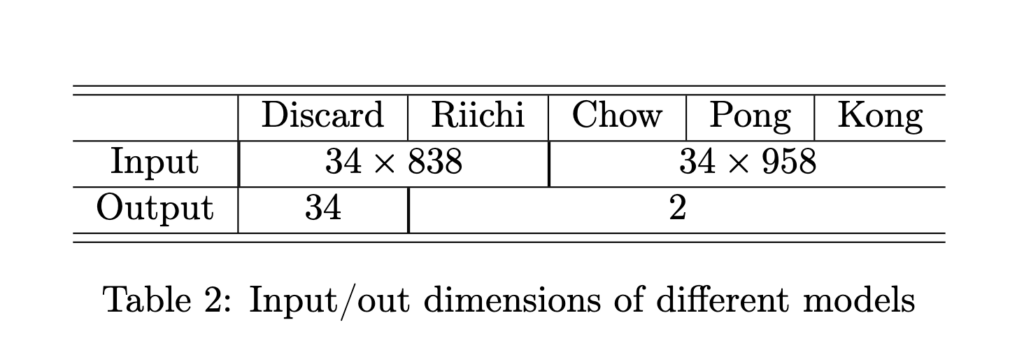
首先,通过阅读论文,我们了解到Suphx在「弃牌模型」和「立直模型」中使用了通道多达838的特征,而「鸣牌模型」用到的特征更是多了120个通道。文中给出了一些比较基本的特征的编码方法,但对于这多达838个通道都是如何编码来的并未详细说明(其实是直接没说),不过,我们完全可以先做一个简化版的出来,日后再慢慢增加特征。
手牌编码
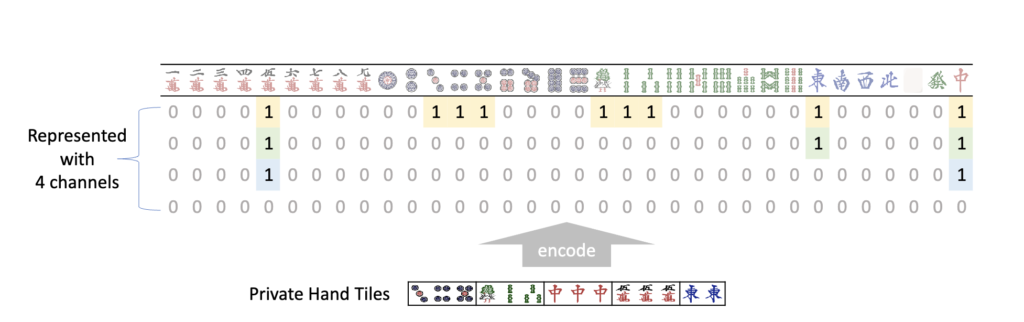
论文的图片已经很形象地说明了手牌的编码方法。该方法将手牌编码为4通道的34维向量,即形状为(4,34)的矩阵。首先将34种牌编码为0-33,当玩家手牌中拥有X张Y(0≤Y≤33)的时候,就将该矩阵第Y列的前X个元素置为1。
为了编码的方便,我们可以为每个Agent维护一个手牌计数器,然后通过下面的函数即可生成编码:
def get_hand_tile_feature(self, counter):
"""
自家手牌
:param counter: Counter
:return: (4, 34)
"""
feature = np.zeros(shape=(4, 34))
upper_triangle = np.tril(np.ones(4))
for tile, c in counter.items():
if c > 0:
feature[:, tile] = upper_triangle[c - 1]
return feature副露编码
通过类似的方法,我们同样可以对玩家的副露进行编码,与手牌不同的是,副露是属于四个玩家均可见的牌,因此需要对四位玩家的副露都进行编码。我使用的编码方法如下:
- 每个副露使用与前面手牌相同的方法编码成形状为(4,34)的矩阵
- 每位玩家都预留4个副露的位置
由此,每位玩家的副露需要16通道,四位玩家的副露则需要64通道。
舍牌编码
与手牌不同,玩家的舍牌是存在序列特性的,同样的舍牌在不同巡目被切出,所蕴含的意义截然不同。例如第一巡就切出的九万,大概率是个孤张,但在20巡左右手切出的九万,周围基本是有牌的。因此对舍牌的编码需要保留舍牌的顺序。考虑到每位玩家最大舍牌数为24,我们将每位玩家的舍牌编码为形状(24,34)的矩阵,每一行为一个onehot向量,表示该巡切出的舍牌编号(0-33)。
因此,四位玩家的舍牌可以被编码为形状(96,34)的矩阵。
场上所有可见牌的编码
考虑到一些防守与做牌策略,场上每种牌出现过的次数是一个有用的特征,我们可以对其进行编码。
基于此,我们可以维护一个计数器用来统计每种牌在全局可见的区域内出现过的次数,这些区域包括「四位玩家的牌河」、「四位玩家的副露区域」、「宝牌指示牌区域」。对每位玩家而言,可见牌还包括自己的手牌,因此,需要编码的可见牌信息为两个计数器之“和”,编码方法则与手牌一模一样,不再赘述。
一些类别特征
论文中提到了一些类别特征:
…categorical features including round id, dealer, counters of repeat dealer, and Riichi bets.
…
Categorical features are encoded into multiple channels, with each channel being either all 0’s or all 1’s.
这些特征包含局数、亲家、连庄数(应该说本场数更为严谨)、立直棒数等。所有类别特征均被编码为全0或全1的通道,我的理解是:总类别数为N时的第n个类别,需要编码为一个(N,34)的全0矩阵,并把第n个通道全部置为1。
def get_category_feature(category, cat_num):
"""
类别特征
:return: (cat_num, 34)
"""
feature = np.zeros(shape=(cat_num, 34))
feature[category].fill(1)
return feature我编码的类别特征以及类别数如下:
| 类别特征 | 类别数 |
|---|---|
| 自家座位 | 4 |
| 自家顺位 | 4 |
| 局顺 | 16 |
| 本场数 | 20 |
| 场供(立直棒)数 | 20 |
| 亲家座位 | 4 |
共计68个通道。
整数特征
有一些信息以整数的形式存在,例如玩家的分数、剩余的牌数等。这些信息也会影响到玩家的决策,因此应该被编码进特征里。如论文中所述:
Integer features are partitioned into buckets and each bucket is encoded using a channel of either all 0’s or all 1’s.
整数特征被分为了多个bucket,然后按类别特征进行编码。
对于玩家的分数,我采用了每5000分一个bucket的形式,从5000分到45000分,共分为9个bucket。而剩余牌数以5、10、22、46为间隔分为5个bucket。
其他特征
此外我还编码了一些比较重要的信息:
- 宝牌
- 门风、场风
- 四家的立直情况
副露模型的额外特征
对于「吃、碰、杠模型」,我额外为其添加了两个特征:
- 鸣牌之后的手牌特征
- 鸣牌之后自家的副露特征
编码方法与前面提到的手牌、副露编码相同。
这些所有特征共组成了288个通道,副露模型则额外增加22个通道,与论文描述的838通道、958通道相差甚远。值得一提的是,论文中提到了一个前瞻特征(look-ahead feature):
In addition to the directly observable information, we also design some look-ahead features, which indicate the probability and round score of winning a hand if we discard a specific tile from the current hand tiles and then draw tiles from the wall to replace some other hand tiles.
…we make several simplifications while extracting look-ahead features: (1) We perform depth first search to find possible winning hands. (2) We ignore opponents’ behaviors and only consider drawing and discarding behaviors of our own agent. With those simplifications, we obtain 100+ look-ahead features, with each feature corresponding to a 34-dimensional vector. For example, a feature represents whether discarding a specific tile can lead to a winning hand of 12,000 round score with replacing 3 hand tiles by tiles drawn from the wall or discarded by other players.
这一系列特征我还没有进行设计(另外,由于这些特征的构建需要用到dfs,是否会对训练速度有较大的影响?)希望能有大佬指点迷津。
至此,特征的构建已基本完成,虽然特征通道数远远小于论文所写,但对于我们想复现的迷你版模型而言,或许已经足够了,这样一来,监督学习所需要的要素已经收集完全。
由于科研繁忙,对于Suphx论文中提到的强化学习算法的复现计划得暂时往后放一放了(但写几篇博客的时间还是有的),后面的文章中,我应该会先写一些杂七杂八的项目实现中的细节问题。
 V me 50!
V me 50!- Alipay is also ok~